Tutorial 1: A basic introduction to pysumma functionality¶
This notebook gives a brief overview of pysumma functions.
It was originally created by Bart Nijssen and Andrew Bennett (University of Washington) for the “CUAHSI Virtual University snow modeling course 2019”. Modifications include a change of data and update of the naming scheme to comply with SUMMA v3.0. Source: https://github.com/bartnijssen/cuahsi_vu_2019
Loading the required modules¶
[1]:
%pylab inline
%load_ext autoreload
%autoreload 2
%reload_ext autoreload
import pysumma as ps
import pysumma.plotting as psp
import matplotlib.pyplot as plt
!cd data/reynolds && ./install_local_setup.sh && cd -
/home/bzq/workspace/pysumma/tutorial
Instantiating a simulation object¶
To set up a Simulation object you must supply 2 pieces of information.
Simulation object you can then just pass these to the constructor as shown below.[2]:
# Define location of .exe and file manager
executable = 'summa.exe'
file_manager = './data/reynolds/file_manager.txt'
[3]:
# Create a model instance
s = ps.Simulation(executable, file_manager)
Manipulating the configuration of the simulation object¶
Most of your interactions with pysumma will be facilitated through this Simulation object, so let’s take some time to look through what is in it. What’s contained in the Simulation object right after instantiation is generally just the input required for a SUMMA run. For a more in depth discussion of what these are see the SUMMA Input page of the documentation. There are several attributes of interest that can be
examined. To see each of them you can simply print them. Here’s a very high level overview of what’s available:
s.manager- the file managers.decisions- the decisions files.output_control- defines what variables to write outs.force_file_list- a listing of all of the forcing files to uses.local_attributes- describes GRU/HRU attributes (lat, lon, elevation, etc)s.global_hru_params- listing of spatially constant local (HRU) parameter valuess.global_gru_params- listing of spatially constant basin (GRU) parameter valuess.trial_params- spatially distributed parameter values (will overwritelocal_param_infovalues, can be either HRU or GRU)
Most of these objects have a similar interface defined, with exceptions being local_attributes and parameter_trial. Those two are standard xarray datasets. All others follow the simple API:
print(x) # Show the data as SUMMA reads it
x.get_option(NAME) # Get an option
x.set_option(NAME, VALUE) # Change an option
x.remove_option(NAME) # Remove an option
More intuitively, you can use key - value type indexing like dictionaries, dataframes, and datasets:
print(x['key']) # Get an option
x['key'] = value # Change an option
File manager¶
Let’s take a look at what the file manager text file actually contains:
[4]:
s.manager
[4]:
controlVersion 'SUMMA_FILE_MANAGER_V3.0.0'
simStartTime '1999-10-01 01:00'
simEndTime '2002-09-30 23:00'
tmZoneInfo 'localTime'
settingsPath '/home/bzq/workspace/pysumma/tutorial/data/reynolds/settings/'
forcingPath '/home/bzq/workspace/pysumma/tutorial/data/reynolds/forcing/'
outputPath '/home/bzq/workspace/pysumma/tutorial/data/reynolds/output/'
decisionsFile 'snow_zDecisions.txt'
outputControlFile 'snow_zOutputControl.txt'
globalHruParamFile 'snow_zLocalParamInfo.txt'
globalGruParamFile 'snow_zBasinParamInfo.txt'
attributeFile 'snow_zLocalAttributes.nc'
trialParamFile 'snow_zParamTrial.nc'
forcingListFile 'forcing_file_list.txt'
initConditionFile 'snow_zInitCond.nc'
outFilePrefix 'reynolds'
vegTableFile 'VEGPARM.TBL'
soilTableFile 'SOILPARM.TBL'
generalTableFile 'GENPARM.TBL'
noahmpTableFile 'MPTABLE.TBL'These are the file paths and names as the simulation object s knows them. You can compare this to the contents of the file ./pbhm-exercise-2/settings/reynolds/summa_fileManager_reynoldsConstantDecayRate.txt to see that they are identical. For this exercise, we’ll focus on three items: the model decisions or parametrizations, parameter values and output control.
Setting decisions¶
So, now that we’ve got a handle on what’s available and what you can do with it, let’s actually try some of this out. First let’s just print out our decisions file so we can see what’s in the defaults. Note that this only prints the decisions specified in the decision file (./pbhm-exercise-2/settings/reynolds/summa_zDecisions_reynoldsConstantDecayRate.txt) and not all the model decisions that can be made in SUMMA. For a full overview of modelling decision, see the SUMMA documentation:
https://summa.readthedocs.io/en/master/input_output/SUMMA_input/#infile_model_decisions
[5]:
s.decisions
[5]:
soilCatTbl ROSETTA ! soil-category dataset
vegeParTbl USGS ! vegetation-category dataset
soilStress NoahType ! choice of function for the soil moisture control on stomatal resistance
stomResist BallBerry ! choice of function for stomatal resistance
num_method itertive ! choice of numerical method
fDerivMeth analytic ! choice of method to calculate flux derivatives
LAI_method monTable ! choice of method to determine LAI and SAI
f_Richards mixdform ! form of Richards equation
groundwatr qTopmodl ! choice of groundwater parameterization
hc_profile pow_prof ! choice of hydraulic conductivity profile
bcUpprTdyn nrg_flux ! type of upper boundary condition for thermodynamics
bcLowrTdyn zeroFlux ! type of lower boundary condition for thermodynamics
bcUpprSoiH liq_flux ! type of upper boundary condition for soil hydrology
bcLowrSoiH zeroFlux ! type of lower boundary condition for soil hydrology
veg_traits CM_QJRMS1988 ! choice of parameterization for vegetation roughness length and displacement height
rootProfil powerLaw ! choice of parameterization for the rooting profile
canopyEmis difTrans ! choice of parameterization for canopy emissivity
snowIncept lightSnow ! choice of parameterization for snow interception
windPrfile logBelowCanopy ! choice of canopy wind profile
astability louisinv ! choice of stability function
canopySrad BeersLaw ! choice of method for canopy shortwave radiation
alb_method varDecay ! choice of albedo representation
compaction anderson ! choice of compaction routine
snowLayers CLM_2010 ! choice of method to combine and sub-divide snow layers
thCondSnow jrdn1991 ! choice of thermal conductivity representation for snow
thCondSoil funcSoilWet ! choice of thermal conductivity representation for soil
spatial_gw localColumn ! choice of method for spatial representation of groundwater
subRouting timeDlay ! choice of method for sub-grid routing
snowDenNew constDens ! choice of method for new snow densityGreat, we can see what’s in there. But to be able to change anything we need to know the available options for each decision. Let’s look at how to do that. For arbitrary reasons we will look at the snowIncept option, which describes the parameterization for snow interception in the canopy. First we will get it from the decisions object directly, and then query what it can be changed to, then finally change the value to something else.
[6]:
# Get just the `snowIncept` option
print(s.decisions['snowIncept'])
# Look at what we can set it to
print(s.decisions['snowIncept'].available_options)
# Change the value
s.decisions['snowIncept'] = 'stickySnow'
print(s.decisions['snowIncept'])
snowIncept lightSnow ! choice of parameterization for snow interception
['stickySnow', 'lightSnow']
snowIncept stickySnow ! choice of parameterization for snow interception
Changing parameters¶
Much like the decisions we can manipulate the gloabl_hru_param file. First, let’s look at what’s contained in it:
[7]:
print(s.global_hru_params)
upperBoundHead | -7.5d-1 | -1.0d+2 | -1.0d-2
lowerBoundHead | 0.0000 | -1.0d+2 | -1.0d-2
upperBoundTheta | 0.2004 | 0.1020 | 0.3680
lowerBoundTheta | 0.1100 | 0.1020 | 0.3680
upperBoundTemp | 272.1600 | 270.1600 | 280.1600
lowerBoundTemp | 274.1600 | 270.1600 | 280.1600
tempCritRain | 273.1600 | 272.1600 | 274.1600
tempRangeTimestep | 2.0000 | 0.5000 | 5.0000
frozenPrecipMultip | 1.0000 | 0.5000 | 1.5000
snowfrz_scale | 50.0000 | 10.0000 | 1000.0000
fixedThermalCond_snow | 0.3500 | 0.1000 | 1.0000
albedoMax | 0.8400 | 0.7000 | 0.9500
albedoMinWinter | 0.5500 | 0.6000 | 1.0000
albedoMinSpring | 0.5500 | 0.3000 | 1.0000
albedoMaxVisible | 0.9500 | 0.7000 | 0.9500
albedoMinVisible | 0.7500 | 0.5000 | 0.7500
albedoMaxNearIR | 0.6500 | 0.5000 | 0.7500
albedoMinNearIR | 0.3000 | 0.1500 | 0.4500
albedoDecayRate | 1.0d+6 | 1.0d+5 | 5.0d+6
albedoSootLoad | 0.3000 | 0.1000 | 0.5000
albedoRefresh | 1.0000 | 1.0000 | 10.0000
radExt_snow | 20.0000 | 20.0000 | 20.0000
Frad_direct | 0.7000 | 0.0000 | 1.0000
Frad_vis | 0.5000 | 0.0000 | 1.0000
directScale | 0.0900 | 0.0000 | 0.5000
newSnowDenMin | 100.0000 | 50.0000 | 100.0000
newSnowDenMult | 100.0000 | 25.0000 | 75.0000
newSnowDenScal | 5.0000 | 1.0000 | 5.0000
constSnowDen | 100.0000 | 50.0000 | 250.0000
newSnowDenAdd | 109.0000 | 80.0000 | 120.0000
newSnowDenMultTemp | 6.0000 | 1.0000 | 12.0000
newSnowDenMultWind | 26.0000 | 16.0000 | 36.0000
newSnowDenMultAnd | 1.0000 | 1.0000 | 3.0000
newSnowDenBase | 0.0000 | 0.0000 | 0.0000
densScalGrowth | 0.0460 | 0.0230 | 0.0920
tempScalGrowth | 0.0400 | 0.0200 | 0.0600
grainGrowthRate | 2.7d-6 | 1.0d-6 | 5.0d-6
densScalOvrbdn | 0.0230 | 0.0115 | 0.0460
tempScalOvrbdn | 0.0800 | 0.6000 | 1.0000
baseViscosity | 9.0d+5 | 5.0d+5 | 1.5d+6
Fcapil | 0.0600 | 0.0100 | 0.1000
k_snow | 0.0150 | 0.0050 | 0.0500
mw_exp | 3.0000 | 1.0000 | 5.0000
z0Snow | 0.0010 | 0.0010 | 10.0000
z0Soil | 0.0100 | 0.0010 | 10.0000
z0Canopy | 0.1000 | 0.0010 | 10.0000
zpdFraction | 0.6500 | 0.5000 | 0.8500
critRichNumber | 0.2000 | 0.1000 | 1.0000
Louis79_bparam | 9.4000 | 9.2000 | 9.6000
Louis79_cStar | 5.3000 | 5.1000 | 5.5000
Mahrt87_eScale | 1.0000 | 0.5000 | 2.0000
leafExchangeCoeff | 0.0100 | 0.0010 | 0.1000
windReductionParam | 0.2800 | 0.0000 | 1.0000
soil_dens_intr | 2700.0000 | 500.0000 | 4000.0000
thCond_soil | 5.5000 | 2.9000 | 8.4000
frac_sand | 0.1600 | 0.0000 | 1.0000
frac_silt | 0.2800 | 0.0000 | 1.0000
frac_clay | 0.5600 | 0.0000 | 1.0000
fieldCapacity | 0.2000 | 0.0000 | 1.0000
theta_mp | 0.4010 | 0.3000 | 0.6000
theta_sat | 0.5500 | 0.3000 | 0.6000
theta_res | 0.1390 | 0.0010 | 0.1000
vGn_alpha | -8.4d-1 | -1.0d+0 | -1.0d-2
vGn_n | 1.3000 | 1.0000 | 3.0000
mpExp | 5.0000 | 1.0000 | 10.0000
wettingFrontSuction | 0.3000 | 0.1000 | 1.5000
k_soil | 7.5d-6 | 1.0d-7 | 1.0d-5
k_macropore | 0.0010 | 1.0d-7 | 1.0d-5
kAnisotropic | 1.0000 | 0.0001 | 10.0000
zScale_TOPMODEL | 2.5000 | 0.1000 | 100.0000
compactedDepth | 1.0000 | 0.0000 | 1.0000
aquiferScaleFactor | 0.3500 | 0.1000 | 100.0000
aquiferBaseflowExp | 2.0000 | 1.0000 | 10.0000
aquiferBaseflowRate | 2.0000 | 1.0000 | 10.0000
qSurfScale | 50.0000 | 1.0000 | 100.0000
specificYield | 0.2000 | 0.1000 | 0.3000
specificStorage | 1.0d-9 | 1.0d-5 | 1.0d-7
f_impede | 2.0000 | 1.0000 | 10.0000
soilIceScale | 0.1300 | 0.0001 | 1.0000
soilIceCV | 0.4500 | 0.1000 | 5.0000
Kc25 | 296.0770 | 296.0770 | 296.0770
Ko25 | 0.2961 | 0.2961 | 0.2961
Kc_qFac | 2.1000 | 2.1000 | 2.1000
Ko_qFac | 1.2000 | 1.2000 | 1.2000
kc_Ha | 7.9d+4 | 7.9d+4 | 7.9d+4
ko_Ha | 3.6d+4 | 3.6d+4 | 3.6d+4
vcmax25_canopyTop | 40.0000 | 20.0000 | 100.0000
vcmax_qFac | 2.4000 | 2.4000 | 2.4000
vcmax_Ha | 6.5d+4 | 6.5d+4 | 6.5d+4
vcmax_Hd | 2.2d+5 | 1.5d+5 | 1.5d+5
vcmax_Sv | 710.0000 | 485.0000 | 485.0000
vcmax_Kn | 0.6000 | 0.0000 | 1.2000
jmax25_scale | 2.0000 | 2.0000 | 2.0000
jmax_Ha | 4.4d+4 | 4.4d+4 | 4.4d+4
jmax_Hd | 1.5d+5 | 1.5d+5 | 1.5d+5
jmax_Sv | 495.0000 | 495.0000 | 495.0000
fractionJ | 0.1500 | 0.1500 | 0.1500
quantamYield | 0.0500 | 0.0500 | 0.0500
vpScaleFactor | 1500.0000 | 1500.0000 | 1500.0000
cond2photo_slope | 9.0000 | 1.0000 | 10.0000
minStomatalConductance | 2000.0000 | 2000.0000 | 2000.0000
winterSAI | 1.0000 | 0.0100 | 3.0000
summerLAI | 3.0000 | 0.0100 | 10.0000
rootScaleFactor1 | 2.0000 | 1.0000 | 10.0000
rootScaleFactor2 | 5.0000 | 1.0000 | 10.0000
rootingDepth | 3.0000 | 0.0100 | 10.0000
rootDistExp | 1.0000 | 0.0100 | 1.0000
plantWiltPsi | -1.5d+2 | -5.0d+2 | 0.0000
soilStressParam | 5.8000 | 4.3600 | 6.3700
critSoilWilting | 0.0750 | 0.0000 | 1.0000
critSoilTranspire | 0.1750 | 0.0000 | 1.0000
critAquiferTranspire | 0.2000 | 0.1000 | 10.0000
minStomatalResistance | 50.0000 | 10.0000 | 200.0000
leafDimension | 0.0400 | 0.0100 | 0.1000
heightCanopyTop | 20.0000 | 0.0500 | 100.0000
heightCanopyBottom | 2.0000 | 0.0000 | 5.0000
specificHeatVeg | 874.0000 | 500.0000 | 1500.0000
maxMassVegetation | 25.0000 | 1.0000 | 50.0000
throughfallScaleSnow | 0.5000 | 0.1000 | 0.9000
throughfallScaleRain | 0.5000 | 0.1000 | 0.9000
refInterceptCapSnow | 6.6000 | 1.0000 | 10.0000
refInterceptCapRain | 1.0000 | 0.0100 | 1.0000
snowUnloadingCoeff | 0.0000 | 0.0000 | 1.5d-6
canopyDrainageCoeff | 0.0050 | 0.0010 | 0.0100
ratioDrip2Unloading | 0.4000 | 0.0000 | 1.0000
canopyWettingFactor | 0.7000 | 0.0000 | 1.0000
canopyWettingExp | 1.0000 | 0.0000 | 1.0000
minwind | 0.1000 | 0.0010 | 1.0000
minstep | 1.0000 | 1.0000 | 1800.0000
maxstep | 3600.0000 | 60.0000 | 1800.0000
wimplicit | 0.0000 | 0.0000 | 1.0000
maxiter | 100.0000 | 1.0000 | 100.0000
relConvTol_liquid | 0.0010 | 1.0d-5 | 0.1000
absConvTol_liquid | 1.0d-5 | 1.0d-8 | 0.0010
relConvTol_matric | 1.0d-6 | 1.0d-5 | 0.1000
absConvTol_matric | 1.0d-6 | 1.0d-8 | 0.0010
relConvTol_energy | 0.0100 | 1.0d-5 | 0.1000
absConvTol_energy | 1.0000 | 0.0100 | 10.0000
relConvTol_aquifr | 1.0000 | 0.0100 | 10.0000
absConvTol_aquifr | 1.0d-5 | 1.0d-5 | 0.1000
zmin | 0.0100 | 0.0050 | 0.1000
zmax | 0.0750 | 0.0100 | 0.5000
zminLayer1 | 0.0075 | 0.0075 | 0.0075
zminLayer2 | 0.0100 | 0.0100 | 0.0100
zminLayer3 | 0.0500 | 0.0500 | 0.0500
zminLayer4 | 0.1000 | 0.1000 | 0.1000
zminLayer5 | 0.2500 | 0.2500 | 0.2500
zmaxLayer1_lower | 0.0500 | 0.0500 | 0.0500
zmaxLayer2_lower | 0.2000 | 0.2000 | 0.2000
zmaxLayer3_lower | 0.5000 | 0.5000 | 0.5000
zmaxLayer4_lower | 1.0000 | 1.0000 | 1.0000
zmaxLayer1_upper | 0.0300 | 0.0300 | 0.0300
zmaxLayer2_upper | 0.1500 | 0.1500 | 0.1500
zmaxLayer3_upper | 0.3000 | 0.3000 | 0.3000
zmaxLayer4_upper | 0.7500 | 0.7500 | 0.7500
minTempUnloading | 270.1600 | 260.1600 | 273.1600
minWindUnloading | 0.0000 | 0.0000 | 10.0000
rateTempUnloading | 1.9d+5 | 1.0d+5 | 3.0d+5
rateWindUnloading | 1.6d+5 | 1.0d+5 | 3.0d+5
Yikes, that’s pretty long. Let’s change something for the sake of it:
[8]:
# Print it
print('old: ' + str(s.global_hru_params['albedoMax']))
# Change the value
s.global_hru_params['albedoMax'] = 0.9
print('new: ' + str(s.global_hru_params['albedoMax']))
old: albedoMax | 0.8400 | 0.7000 | 0.9500
new: albedoMax | 0.9000 | 0.9000 | 0.9000
Modifying output¶
And one more, we can also modify what get’s written to output. The output control file represents the options available through columns of numeric values. These numbers represent how to write the output. From the SUMMA documentation (https://summa.readthedocs.io/en/latest/input_output/SUMMA_input/#output-control-file) they are arranged as:
! varName | outFreq | inst | sum | mean | var | min | max | mode
As before, let’s look at what’s in the output_control by simply printing it out:
[9]:
print(s.output_control)
nSnow | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarSWE | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarSnowDepth | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarSnowfallTemp | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarSnowAge | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarInfiltration | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarExfiltration | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarTotalSoilLiq | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarTotalSoilIce | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarSurfaceRunoff | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarSurfaceTemp | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarSnowSublimation | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarLatHeatTotal | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarSenHeatTotal | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarSnowDrainage | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarRainfall | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
scalarSnowfall | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
mLayerVolFracIce | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
mLayerVolFracLiq | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
mLayerVolFracWat | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
mLayerDepth | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
mLayerTemp | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
mLayerHeight | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
iLayerHeight | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
iLayerNrgFlux | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
mLayerNrgFlux | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
mLayerLiqFluxSnow | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
iLayerLiqFluxSnow | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
iLayerConductiveFlux | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
iLayerAdvectiveFlux | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
Note that SUMMA is pretty flexible in its output. What we see above is a pretty typical output file configuration that contains most of the major state variables and fluxes. For a more complete overview of what you can ask SUMMA to output, see: https://github.com/NCAR/summa/blob/master/build/source/dshare/var_lookup.f90
We can modify values in the existing output_control in a couple of ways:
[10]:
# Check the settings for one of the output variables
print(s.output_control['scalarInfiltration'])
print(s.output_control['scalarInfiltration'].statistic)
# Change the output statistic from instantaneous to sum
s.output_control['scalarInfiltration'] = [1, 1, 0, 0, 0, 0, 0, 0]
print(s.output_control['scalarInfiltration'])
print(s.output_control['scalarInfiltration'].statistic)
# We could also be more verbose:
s.output_control['scalarInfiltration'] = {
'period': 1, 'instant': 1, 'sum': 0,
'mean': 0, 'variance': 0, 'min': 0, 'max': 0
}
print(s.output_control['scalarInfiltration'])
print(s.output_control['scalarInfiltration'].statistic)
scalarInfiltration | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
instant
scalarInfiltration | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0
sum
scalarInfiltration | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0
instant
Running pysumma and manipulating output¶
Now that you’ve had an overview of how you can interact with SUMMA configurations through pysumma let’s run a simulation. Before doing so we will reset our Simulation object, which will discard all of the changes we’ve made and load in a clean setup. Alternatively you could simply instantiate a new Simulation object. After running the simulation, we will make sure that it completed successfully by checking the status. With a complete run, we can look at the output simply by using the
simulation’s output attribute. It is simply an xarray dataset, which can be manipulated in all of the usual ways.
[11]:
s.reset()
# Or you could just create a new simulation object like before:
#s = ps.Simulation(executable, file_manager)
Before we run the model, we need to ensure that the output directory specified in the fileManger actually exists. If it doesn’t, SUMMA will notify you of this and abort the simulation.
[12]:
# module to handle tasks related to files and folders
import os
# Make the output directory if it doesn't exist
print('Current specified output directory: ' + s.manager['outputPath'].value)
if not os.path.exists(s.manager['outputPath'].value):
os.makedirs(s.manager['outputPath'].value)
Current specified output directory: /home/bzq/workspace/pysumma/tutorial/data/reynolds/output/
Now we can try a model run.
[13]:
s.run('local', run_suffix='_default') # run_suffix allows you to specify a string that will be added to the output file name. This is very useful to keep track of different experiments
print(s.status)
Success
You should have gotten a 'Success' printed out after running the simulation. For further details about the simulation you can look at the full output log that SUMMA produces by printing out s.stdout. In the event that s.status does not return Success you may wish to inspect this log to diagnose the problem further. s.stderror and s.stdout can provide details about the error.
Plotting¶
Now that we’ve got some output we can plot some results. Because the output is an xarray DataSet we can use the convenient plotting capabilities provided by xarray.
[14]:
s.output['scalarSWE'].plot(label='SUMMA');
plt.legend(); # note that 'plt' relies on: 'import matplotlib.pyplot as plt' which is magically included in the line `%pylab inline` in the first code block
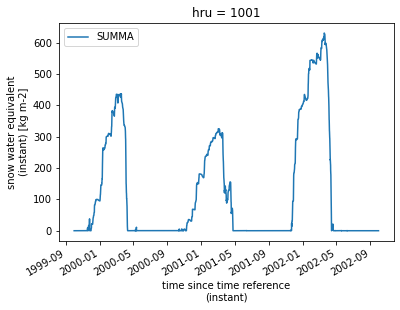
Additionally, pysumma provides some more specialized plotting capabilities. To access it we have the ps.plotting module. First, lets plot the vertical layers over time. For this we will use ps.plotting.layers, which requires two pieces of information. First, the variable that you want to plot. It should have both time and midToto dimensions. The first plot we will make will be the temperature, which uses the variable mLayerTemp, and the second will be the volumetric fraction
of water content in each layer, which uses mLayerVolFracWat. To start out we will give these more convenient names.
[15]:
depth = s.output.isel(hru=0)['iLayerHeight']
temp = s.output.isel(hru=0)['mLayerTemp']
frac_wat = s.output.isel(hru=0)['mLayerVolFracWat']
Now we can plot this using our function. For the temperature plot we will set plot_soil to False so that we only plot the snowpack. We can see that the top layers of the snowpack respond more quickly to the changing air temperature, and that later in the season the warmer air causes temperature transmission to lower layers and ultimately melts out.
[16]:
psp.layers(temp, depth, colormap='viridis', plot_soil=False, plot_snow=True);
s.output['scalarSnowDepth'].plot(color='red', linewidth=2);
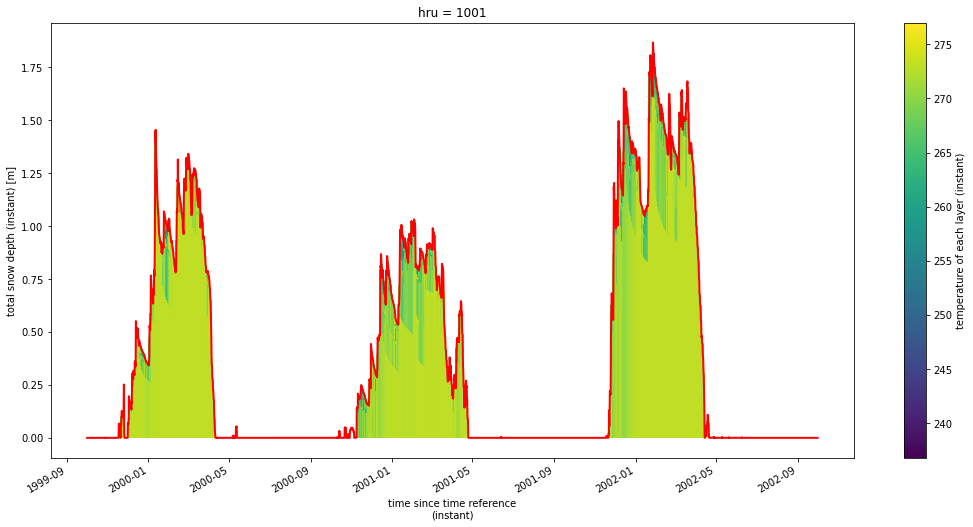
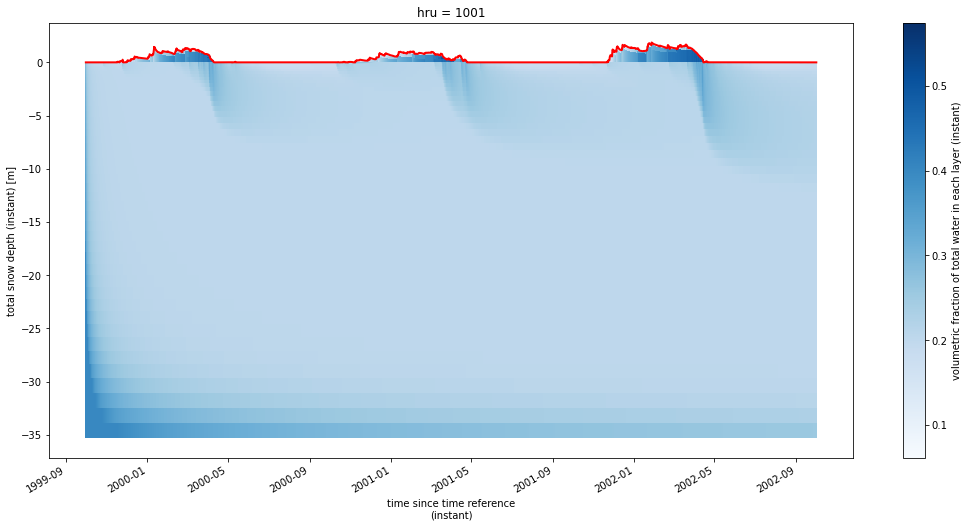
By looking at the volumetric water content we can see even more details. Now we will set plot_soil to True so that we can see how snowmelt can cause water infiltration into the soil. For example, during the melt season in 2012 we can easily see how the snowmelt infiltrates into the ground.
[17]:
psp.layers(frac_wat, depth, colormap='Blues', plot_soil=True, plot_snow=True);
s.output['scalarSnowDepth'].plot(color='red', linewidth=2);
[ ]:
Tutorial 2: Running ensembles of SUMMA simulations¶
pysumma offers an Ensemble class which is useful for running multiple simulations with varying options. These options can be parameter values, model structures, different locations made up of different file managers, or combinations of any of these. To demonstrate the Ensemble capabilities we will step through each individually. As usual we will begin with some imports and definition of some global variables.
[1]:
import numpy as np
import pysumma as ps
import matplotlib.pyplot as plt
from pprint import pprint
!cd data/reynolds && ./install_local_setup.sh && cd -
!cd data/coldeport && ./install_local_setup.sh && cd -
summa_exe = 'summa.exe'
file_manager = './data/coldeport/file_manager.txt'
/home/bzq/workspace/pysumma/tutorial
/home/bzq/workspace/pysumma/tutorial
Changing decisions¶
The Ensemble object mainly operates by taking configuration dictionaries. These can be defined manually, or can be defined through the use of helper functions which will be described later. For now, we will look at how to run models using different options for the stomResist and soilStress decisions. This is done by providing a dictionary of these mappings inside of a decisions key of the overall configuration. The decisions key is one of several special configuration keys
which pysumma knows how to manipulate under the hood. We will explore the others later.
This configuration is used to construct the Ensemble object, which also takes the SUMMA executable, a file manager path, and optionally the num_workers argument. The num_workers argument is used to automatically run these ensemble members in parallel. Here we define it as 2, since that’s how many different runs we will be completing. You can set this to a higher number than your computer has CPU cores, but you won’t likely see any additional speedup by doing so.
We then run the ensemble through the run method which works similarly to the Simulation object. After running the ensemble we check the status by running the summary method. This will return a dictionary outlining any successes or failures of each of the members. In the event of any failures you can later inspect the underlying Simulation objects that are internal to the Ensemble. We will demonstrate how to do this later in the tutorial.
[2]:
config = {
'run0': {'decisions':{'stomResist': 'Jarvis',
'soilStress': 'NoahType'}},
'run1': {'decisions':{'stomResist': 'BallBerry',
'soilStress': 'CLM_Type'}},
}
decision_ens = ps.Ensemble(summa_exe, config, file_manager, num_workers=2)
decision_ens.run('local')
print(decision_ens.summary())
{'Success': ['run0', 'run1'], 'Error': [], 'Other': []}
We also provide some functionality to make it easier to wrangle the data together via the merge_output method.
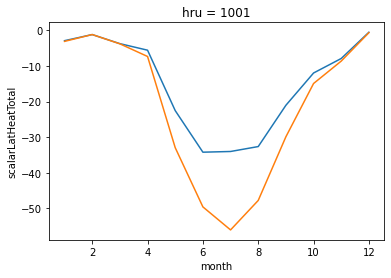
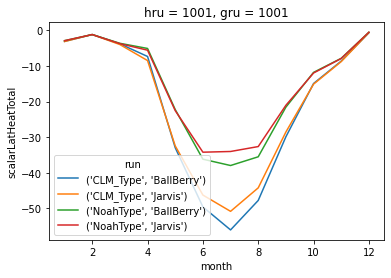
To access the simulations individually you can use the .simulations attribute, which is simply a dictionary of the Simulation objects mapped by the name that’s used to run the simulation. Let’s loop through and print the decisions directly from the Simulation as proof things worked. We can also open the output of each of the simulations as in the previous tutorial, and plot the monthly average latent heat flux for each simulation.
[3]:
for n, sim in decision_ens.simulations.items():
print(f'{n} used {sim.decisions["stomResist"].value} for the stomResist option and {sim.decisions["soilStress"].value} for soilStress')
run0 used Jarvis for the stomResist option and NoahType for soilStress
run1 used BallBerry for the stomResist option and CLM_Type for soilStress
[4]:
run0 = decision_ens.simulations['run0'].output.load()
run1 = decision_ens.simulations['run1'].output.load()
run0['scalarLatHeatTotal'].groupby(run0['time'].dt.month).mean().plot(label='run0')
run1['scalarLatHeatTotal'].groupby(run1['time'].dt.month).mean().plot(label='run1')
[4]:
[<matplotlib.lines.Line2D at 0x7f8f1a631790>]
Note in the previous example we didn’t run every combination of
stomResistandsoilStressthat we could have. When running multiple configurations it often becomes unwieldy to type out the full configuration that you are attempting to run, so some helper functions have been implemented to make this a bit easier. In the following cell we demonstrate this. You can see that the new output will show we have 4 configurations to run, each with a unique set of decisions. The names are just the
decisions being set, delimited by ++ so that it is easy to keep track of each run.
[5]:
decisions_to_run = {
'stomResist': ['Jarvis', 'BallBerry'],
'soilStress': ['NoahType', 'CLM_Type']
}
config = ps.ensemble.decision_product(decisions_to_run)
pprint(config)
{'++BallBerry++CLM_Type++': {'decisions': {'soilStress': 'CLM_Type',
'stomResist': 'BallBerry'}},
'++BallBerry++NoahType++': {'decisions': {'soilStress': 'NoahType',
'stomResist': 'BallBerry'}},
'++Jarvis++CLM_Type++': {'decisions': {'soilStress': 'CLM_Type',
'stomResist': 'Jarvis'}},
'++Jarvis++NoahType++': {'decisions': {'soilStress': 'NoahType',
'stomResist': 'Jarvis'}}}
[6]:
decision_ens = ps.Ensemble(summa_exe, config, file_manager, num_workers=4)
decision_ens.run('local')
print(decision_ens.summary())
{'Success': ['++Jarvis++NoahType++', '++Jarvis++CLM_Type++', '++BallBerry++NoahType++', '++BallBerry++CLM_Type++'], 'Error': [], 'Other': []}
When ensembles have been run through these product configurations (we’ll detail a couple others later), you can use a special method to open them in a way that makes the output easier to wrangle. As before we’ll plot the mean monthly latent heat for each of the runs.
[7]:
ens_ds = decision_ens.merge_output()
ens_ds
[7]:
<xarray.Dataset>
Dimensions: (gru: 1, hru: 1, ifcSnow: 6, ifcToto: 15, midToto: 14, soilStress: 2, stomResist: 2, time: 52585)
Coordinates:
* time (time) datetime64[ns] 1994-10-01T00:59:59.99998659...
* hru (hru) int64 1001
* gru (gru) int64 1001
* stomResist (stomResist) object 'BallBerry' 'Jarvis'
* soilStress (soilStress) object 'CLM_Type' 'NoahType'
Dimensions without coordinates: ifcSnow, ifcToto, midToto
Data variables:
nSnow (time, hru, stomResist, soilStress) int32 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarSnowDepth (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarSWE (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
mLayerTemp (time, midToto, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
mLayerVolFracIce (time, midToto, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
mLayerVolFracLiq (time, midToto, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
mLayerVolFracWat (time, midToto, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
scalarSurfaceTemp (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
mLayerDepth (time, midToto, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
mLayerHeight (time, midToto, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
iLayerHeight (time, ifcToto, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 15, 1, 1, 2), meta=np.ndarray>
scalarSnowfallTemp (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarSnowAge (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarTotalSoilLiq (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarTotalSoilIce (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarRainfall (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarSnowfall (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarSenHeatTotal (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarLatHeatTotal (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarSnowSublimation (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
iLayerConductiveFlux (time, ifcToto, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 15, 1, 1, 2), meta=np.ndarray>
iLayerAdvectiveFlux (time, ifcToto, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 15, 1, 1, 2), meta=np.ndarray>
iLayerNrgFlux (time, ifcToto, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 15, 1, 1, 2), meta=np.ndarray>
mLayerNrgFlux (time, midToto, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
scalarSnowDrainage (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
iLayerLiqFluxSnow (time, ifcSnow, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 6, 1, 1, 2), meta=np.ndarray>
scalarInfiltration (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarExfiltration (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
scalarSurfaceRunoff (time, hru, stomResist, soilStress) float64 dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
hruId (hru, stomResist, soilStress) int64 dask.array<chunksize=(1, 1, 2), meta=np.ndarray>
gruId (gru, stomResist, soilStress) int64 dask.array<chunksize=(1, 1, 2), meta=np.ndarray>
Attributes:
summaVersion: v3.0.3
buildTime: Tue Nov 10 23:53:25 UTC 2020
gitBranch: tags/v3.0.3-0-g4ee457d
gitHash: 4ee457df3d3c0779696c6388c67962ba76736df9
soilCatTbl: ROSETTA
vegeParTbl: MODIFIED_IGBP_MODIS_NOAH
soilStress: NoahType
stomResist: Jarvis
num_method: itertive
fDerivMeth: analytic
LAI_method: monTable
notPopulatedYet: notPopulatedYet
f_Richards: mixdform
groundwatr: qTopmodl
hc_profile: pow_prof
bcUpprTdyn: nrg_flux
bcLowrTdyn: zeroFlux
bcUpprSoiH: liq_flux
bcLowrSoiH: zeroFlux
veg_traits: CM_QJRMS1988
rootProfil: powerLaw
canopyEmis: difTrans
snowIncept: lightSnow
windPrfile: logBelowCanopy
astability: louisinv
canopySrad: BeersLaw
alb_method: conDecay
snowLayers: CLM_2010
compaction: anderson
thCondSnow: smnv2000
thCondSoil: funcSoilWet
spatial_gw: localColumn
subRouting: timeDlay
snowDenNew: constDens- gru: 1
- hru: 1
- ifcSnow: 6
- ifcToto: 15
- midToto: 14
- soilStress: 2
- stomResist: 2
- time: 52585
- time(time)datetime64[ns]1994-10-01T00:59:59.999986592 .....
- long_name :
- time since time reference (instant)
array(['1994-10-01T00:59:59.999986592', '1994-10-01T02:00:00.000013408', '1994-10-01T03:00:00.000000000', ..., '2000-09-29T23:00:00.000013440', '2000-09-30T00:00:00.000000000', '2000-09-30T00:59:59.999986560'], dtype='datetime64[ns]') - hru(hru)int641001
- long_name :
- hruId in the input file
- units :
- -
array([1001])
- gru(gru)int641001
- long_name :
- gruId in the input file
- units :
- -
array([1001])
- stomResist(stomResist)object'BallBerry' 'Jarvis'
array(['BallBerry', 'Jarvis'], dtype=object)
- soilStress(soilStress)object'CLM_Type' 'NoahType'
array(['CLM_Type', 'NoahType'], dtype=object)
- nSnow(time, hru, stomResist, soilStress)int32dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- number of snow layers (instant)
- units :
- -
Array Chunk Bytes 841.36 kB 420.68 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type int32 numpy.ndarray - scalarSnowDepth(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- total snow depth (instant)
- units :
- m
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarSWE(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- snow water equivalent (instant)
- units :
- kg m-2
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - mLayerTemp(time, midToto, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
- long_name :
- temperature of each layer (instant)
- units :
- K
Array Chunk Bytes 23.56 MB 11.78 MB Shape (52585, 14, 1, 2, 2) (52585, 14, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - mLayerVolFracIce(time, midToto, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
- long_name :
- volumetric fraction of ice in each layer (instant)
- units :
- -
Array Chunk Bytes 23.56 MB 11.78 MB Shape (52585, 14, 1, 2, 2) (52585, 14, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - mLayerVolFracLiq(time, midToto, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
- long_name :
- volumetric fraction of liquid water in each layer (instant)
- units :
- -
Array Chunk Bytes 23.56 MB 11.78 MB Shape (52585, 14, 1, 2, 2) (52585, 14, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - mLayerVolFracWat(time, midToto, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
- long_name :
- volumetric fraction of total water in each layer (instant)
- units :
- -
Array Chunk Bytes 23.56 MB 11.78 MB Shape (52585, 14, 1, 2, 2) (52585, 14, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarSurfaceTemp(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- surface temperature (just a copy of the upper-layer temperature) (instant)
- units :
- K
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - mLayerDepth(time, midToto, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
- long_name :
- depth of each layer (instant)
- units :
- m
Array Chunk Bytes 23.56 MB 11.78 MB Shape (52585, 14, 1, 2, 2) (52585, 14, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - mLayerHeight(time, midToto, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
- long_name :
- height of the layer mid-point (top of soil = 0) (instant)
- units :
- m
Array Chunk Bytes 23.56 MB 11.78 MB Shape (52585, 14, 1, 2, 2) (52585, 14, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - iLayerHeight(time, ifcToto, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 15, 1, 1, 2), meta=np.ndarray>
- long_name :
- height of the layer interface (top of soil = 0) (instant)
- units :
- m
Array Chunk Bytes 25.24 MB 12.62 MB Shape (52585, 15, 1, 2, 2) (52585, 15, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarSnowfallTemp(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- temperature of fresh snow (instant)
- units :
- K
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarSnowAge(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- non-dimensional snow age (instant)
- units :
- -
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarTotalSoilLiq(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- total mass of liquid water in the soil (instant)
- units :
- kg m-2
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarTotalSoilIce(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- total mass of ice in the soil (instant)
- units :
- kg m-2
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarRainfall(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- computed rainfall rate (instant)
- units :
- kg m-2 s-1
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarSnowfall(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- computed snowfall rate (instant)
- units :
- kg m-2 s-1
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarSenHeatTotal(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- sensible heat from the canopy air space to the atmosphere (instant)
- units :
- W m-2
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarLatHeatTotal(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- latent heat from the canopy air space to the atmosphere (instant)
- units :
- W m-2
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarSnowSublimation(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- snow sublimation/frost (below canopy or non-vegetated) (instant)
- units :
- kg m-2 s-1
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - iLayerConductiveFlux(time, ifcToto, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 15, 1, 1, 2), meta=np.ndarray>
- long_name :
- conductive energy flux at layer interfaces (instant)
- units :
- W m-2
Array Chunk Bytes 25.24 MB 12.62 MB Shape (52585, 15, 1, 2, 2) (52585, 15, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - iLayerAdvectiveFlux(time, ifcToto, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 15, 1, 1, 2), meta=np.ndarray>
- long_name :
- advective energy flux at layer interfaces (instant)
- units :
- W m-2
Array Chunk Bytes 25.24 MB 12.62 MB Shape (52585, 15, 1, 2, 2) (52585, 15, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - iLayerNrgFlux(time, ifcToto, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 15, 1, 1, 2), meta=np.ndarray>
- long_name :
- energy flux at layer interfaces (instant)
- units :
- W m-2
Array Chunk Bytes 25.24 MB 12.62 MB Shape (52585, 15, 1, 2, 2) (52585, 15, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - mLayerNrgFlux(time, midToto, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 14, 1, 1, 2), meta=np.ndarray>
- long_name :
- net energy flux for each layer within the snow+soil domain (instant)
- units :
- J m-3 s-1
Array Chunk Bytes 23.56 MB 11.78 MB Shape (52585, 14, 1, 2, 2) (52585, 14, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarSnowDrainage(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- drainage from the bottom of the snow profile (instant)
- units :
- m s-1
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - iLayerLiqFluxSnow(time, ifcSnow, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 6, 1, 1, 2), meta=np.ndarray>
- long_name :
- liquid flux at snow layer interfaces (instant)
- units :
- m s-1
Array Chunk Bytes 10.10 MB 5.05 MB Shape (52585, 6, 1, 2, 2) (52585, 6, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarInfiltration(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- infiltration of water into the soil profile (instant)
- units :
- m s-1
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarExfiltration(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- exfiltration of water from the top of the soil profile (instant)
- units :
- m s-1
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - scalarSurfaceRunoff(time, hru, stomResist, soilStress)float64dask.array<chunksize=(52585, 1, 1, 2), meta=np.ndarray>
- long_name :
- surface runoff (instant)
- units :
- m s-1
Array Chunk Bytes 1.68 MB 841.36 kB Shape (52585, 1, 2, 2) (52585, 1, 1, 2) Count 28 Tasks 2 Chunks Type float64 numpy.ndarray - hruId(hru, stomResist, soilStress)int64dask.array<chunksize=(1, 1, 2), meta=np.ndarray>
- long_name :
- ID defining the hydrologic response unit
- units :
- -
Array Chunk Bytes 32 B 16 B Shape (1, 2, 2) (1, 1, 2) Count 28 Tasks 2 Chunks Type int64 numpy.ndarray - gruId(gru, stomResist, soilStress)int64dask.array<chunksize=(1, 1, 2), meta=np.ndarray>
- long_name :
- ID defining the grouped (basin) response unit
- units :
- -
Array Chunk Bytes 32 B 16 B Shape (1, 2, 2) (1, 1, 2) Count 28 Tasks 2 Chunks Type int64 numpy.ndarray
- summaVersion :
- v3.0.3
- buildTime :
- Tue Nov 10 23:53:25 UTC 2020
- gitBranch :
- tags/v3.0.3-0-g4ee457d
- gitHash :
- 4ee457df3d3c0779696c6388c67962ba76736df9
- soilCatTbl :
- ROSETTA
- vegeParTbl :
- MODIFIED_IGBP_MODIS_NOAH
- soilStress :
- NoahType
- stomResist :
- Jarvis
- num_method :
- itertive
- fDerivMeth :
- analytic
- LAI_method :
- monTable
- notPopulatedYet :
- notPopulatedYet
- f_Richards :
- mixdform
- groundwatr :
- qTopmodl
- hc_profile :
- pow_prof
- bcUpprTdyn :
- nrg_flux
- bcLowrTdyn :
- zeroFlux
- bcUpprSoiH :
- liq_flux
- bcLowrSoiH :
- zeroFlux
- veg_traits :
- CM_QJRMS1988
- rootProfil :
- powerLaw
- canopyEmis :
- difTrans
- snowIncept :
- lightSnow
- windPrfile :
- logBelowCanopy
- astability :
- louisinv
- canopySrad :
- BeersLaw
- alb_method :
- conDecay
- snowLayers :
- CLM_2010
- compaction :
- anderson
- thCondSnow :
- smnv2000
- thCondSoil :
- funcSoilWet
- spatial_gw :
- localColumn
- subRouting :
- timeDlay
- snowDenNew :
- constDens
[8]:
stack = ens_ds.isel(hru=0, gru=0).stack(run=['soilStress', 'stomResist'])
stack['scalarLatHeatTotal'].groupby(stack['time'].dt.month).mean(dim='time').plot.line(x='month')
[8]:
[<matplotlib.lines.Line2D at 0x7f8f19713710>,
<matplotlib.lines.Line2D at 0x7f8f19874ad0>,
<matplotlib.lines.Line2D at 0x7f8f19713350>,
<matplotlib.lines.Line2D at 0x7f8f197137d0>]
Changing parameters¶
Similarly, you can change parameter values to do sensitivity experiments:
[17]:
config = {
'lower_param': {'trial_params': {'windReductionParam': 0.1,
'canopyWettingFactor': 0.1}},
'upper_param': {'trial_params': {'windReductionParam': 0.9,
'canopyWettingFactor': 0.9}}
}
param_ens = ps.Ensemble(summa_exe, config, file_manager, num_workers=2)
param_ens.run('local')
print(param_ens.summary())
{'Success': ['lower_param', 'upper_param'], 'Error': [], 'Other': []}
As you can tell, it can quickly become tiresome to type out every parameter value you want to set. To that end we also have a helper function for setting up these parameter sensitivity experiments. Now you can see that we will end up with 4 configurations, as before. We won’t run this because it may take longer than is instructional. But, you can modify this notebook if you wish to see the effect each of these have.
[18]:
parameters_to_run = {
'windReductionParam': [0.1, 0.9],
'canopyWettingFactor': [0.1, 0.9]
}
config = ps.ensemble.trial_parameter_product(parameters_to_run)
pprint(config)
{'++windReductionParam=0.1++canopyWettingFactor=0.1++': {'trial_parameters': {'canopyWettingFactor': 0.1,
'windReductionParam': 0.1}},
'++windReductionParam=0.1++canopyWettingFactor=0.9++': {'trial_parameters': {'canopyWettingFactor': 0.9,
'windReductionParam': 0.1}},
'++windReductionParam=0.9++canopyWettingFactor=0.1++': {'trial_parameters': {'canopyWettingFactor': 0.1,
'windReductionParam': 0.9}},
'++windReductionParam=0.9++canopyWettingFactor=0.9++': {'trial_parameters': {'canopyWettingFactor': 0.9,
'windReductionParam': 0.9}}}
Running multiple sites via file managers¶
As you may have guessed, you can also define an Ensemble by providing a list of file managers. This is useful for running multiple sites which can’t be collected into a multi HRU run because they have different simulation times, are disjointly located, or for any other reason. It is important to note that in this case we don’t provide the Ensemble constructor a file_manager argument, as it is now provided in the configuration.
[20]:
config = {
'coldeport': {'file_manager': './data/coldeport/file_manager.txt'},
'reynolds' : {'file_manager': './data/reynolds/file_manager.txt'},
}
manager_ens = ps.Ensemble(summa_exe, config, num_workers=2)
manager_ens.run('local')
print(manager_ens.summary())
distributed.scheduler - ERROR - Couldn't gather keys {'_submit-261287ecf520a19948af16af51a4eede': []} state: ['processing'] workers: []
NoneType: None
distributed.scheduler - ERROR - Workers don't have promised key: [], _submit-261287ecf520a19948af16af51a4eede
NoneType: None
distributed.client - WARNING - Couldn't gather 1 keys, rescheduling {'_submit-261287ecf520a19948af16af51a4eede': ()}
{'Success': ['coldeport', 'reynolds'], 'Error': [], 'Other': []}
[21]:
managers_to_run = {
'file_manager': ['./data/coldeport/file_manager.txt', './data/coldeport/file_manager.txt']
}
config = ps.ensemble.file_manager_product(managers_to_run)
pprint(config)
{'++file_manager=./data/coldeport/file_manager.txt++': {'file_manager': {'file_manager': './data/coldeport/file_manager.txt'}}}
Combining ensemble types¶
Each of these abilities are useful in their own right, but the ability to combine them into greater ensembles provides a very flexible way to explore multiple hypotheses. To this end we also provide a helper function which can facilitate running these larger experiments. We won’t print out the entire configuration here, since it’s quite long. Instead we show that this would result in 32 SUMMA simulations. For that reason we also won’t run this experment by default, though you can if you wish to.
[22]:
config = ps.ensemble.total_product(dec_conf=decisions_to_run,
param_trial_conf=parameters_to_run,
fman_conf=managers_to_run)
print(len(config))
16
For illustrative purpose we show the first key of this configuration
[23]:
print(list(config.keys())[0])
++Jarvis++NoahType++windReductionParam=0.1++canopyWettingFactor=0.1++._data_coldeport_file_manager.txt++
As you can see, the keys (or names of the runs) grows when you include more options. This can be a problem for some operating systems/filesystems, along with being very hard to read. So, we also have a flag here that makes things more compact
[24]:
config = ps.ensemble.total_product(dec_conf=decisions_to_run,
param_trial_conf=parameters_to_run,
fman_conf=managers_to_run,
sequential_keys=True
)
print(list(config.keys())[0])
run_0
[ ]:
Tutorial 3: Running spatially distributed simulations¶
While the Ensemble class discussed in the previous tutorial can be used to run multiple locations via different file managers, this is generally not the way that a spatially-distributed SUMMA simulation would be run. For spatially-distributed run pysumma has a Distributed class, which makes running these types of simulations easier. For this example we will run a simulation of the Yakima River Basin in the Pacific Northwestern United States. As ususal, we start with some standard imports
and get the model setup installed for local use.
[1]:
import xarray as xr
import pysumma as ps
import geopandas as gpd
import cartopy.crs as ccrs
import pysumma.plotting as psp
import matplotlib.pyplot as plt
!cd data/yakima && ./install_local_setup.sh && cd -
/home/bzq/workspace/pysumma/tutorial
Running a basic Distributed simulation¶
Before getting into any of the further customization that can be done with a Distributed object let’s just run through the basic usage. If you are running this tutorial interactively, you are probably on a small binder instance or other machine that has a small amount of compute capacity. It’s important to point out that in this tutorial we will only run small examples, the parallelism approach of the Distributed object can easily scale out to hundreds of cores. As with the
Simulation and Ensemble objects, a Distributed object must be given a some information, namely the SUMMA executable and a file manager, to be instantiated. Additionally we will set 4 workers, which means that 4 SUMMA simulations will be run in parallel, and the num_chunks to 8. num_chunks describes how many simulations will be run in total. In this configuration each worker will run two SUMMA simulations. We can inspect these chunks directly by inspecting the underlying keys
for the Simulations in the Distributed instance, via yakima.simulations.keys(). Doing so we see that there are 8 simulations, each with 36 GRU (denoted by gX-X+35). As an alternative to the num_chunks argument, you can also use the chunk_size argument to specify how many GRU to run in each chunk.
[2]:
summa_exe = 'summa.exe'
file_manager = './data/yakima/file_manager.txt'
yakima = ps.Distributed(summa_exe, file_manager, num_workers=4, num_chunks=8)
yakima.simulations.keys()
/home/bzq/miniconda3/envs/all/lib/python3.7/site-packages/distributed/node.py:155: UserWarning: Port 8787 is already in use.
Perhaps you already have a cluster running?
Hosting the HTTP server on port 43425 instead
http_address["port"], self.http_server.port
[2]:
dict_keys(['g1-36', 'g37-72', 'g73-108', 'g109-144', 'g145-180', 'g181-216', 'g217-252', 'g253-285'])
As with the Simulation and Ensemble objects we can simply call .run() to start the simulations running. If you are running this tutorial interactively, this may take a moment because of the limited compute capacity of the binder instance. We have included the %%time magic to time how long this cell takes to run locally. You might expect this to take up to roughly two times the amount of time on the binder instance than is reported in the documentation at
pysumma.readthedocs.io. As with the Ensemble we can use the .summary() method once the runs are complete to ensure that they all exit with status Success.
[3]:
%%time
yakima.run()
print(yakima.summary())
{'Success': ['g1-36', 'g37-72', 'g73-108', 'g109-144', 'g145-180', 'g181-216', 'g217-252', 'g253-285'], 'Error': [], 'Other': []}
CPU times: user 10.6 s, sys: 1.93 s, total: 12.5 s
Wall time: 1min 4s
Once you’ve gotten a successful set of simulations, it’s time to look at the output! This can be done with the merge_output() method, which will collate all of the different runs together into a single xr.Dataset. If you want to open each of the output files individually without merging them you can sue the open_output() method. Once we’ve merged everything together, we see that there are 285 GRU (and similarly here, 285 HRU).
[4]:
yakima_ds = yakima.merge_output()
yakima_ds
[4]:
<xarray.Dataset>
Dimensions: (gru: 285, hru: 285, ifcToto: 14, midToto: 13, time: 721)
Coordinates:
* hru (hru) int64 17006965 17006967 ... 17009664
* time (time) datetime64[ns] 2010-06-01 ... 2010...
* gru (gru) int64 906922 906924 ... 909581 909583
Dimensions without coordinates: ifcToto, midToto
Data variables:
pptrate (time, hru) float64 7.562e-05 ... 1.418e-05
airtemp (time, hru) float64 279.2 279.1 ... 278.0
windspd_mean (time, hru) float64 0.8894 0.8894 ... 1.266
SWRadAtm (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
LWRadAtm (time, hru) float64 287.4 287.1 ... 288.3
scalarCanopyIce (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarCanopyLiq (time, hru) float64 0.2849 ... 0.07626
scalarCanopyWat_mean (time, hru) float64 0.2849 ... 0.07626
scalarCanairTemp (time, hru) float64 275.7 275.6 ... 275.8
scalarCanopyTemp (time, hru) float64 275.6 275.5 ... 275.6
scalarSnowAlbedo (time, hru) float64 -9.999e+03 ... -9.999...
scalarSnowDepth_mean (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarSWE (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
mLayerTemp_mean (time, midToto, hru) float64 281.0 ... -9...
scalarSurfaceTemp (time, hru) float64 281.0 281.0 ... 279.2
mLayerDepth_mean (time, midToto, hru) float64 0.025 ... -9...
mLayerHeight_mean (time, midToto, hru) float64 0.0125 ... -...
iLayerHeight_mean (time, ifcToto, hru) float64 -0.0 ... -9....
scalarTotalSoilLiq (time, hru) float64 1.169e+03 ... 1.273e+03
scalarTotalSoilIce (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarCanairNetNrgFlux (time, hru) float64 -5.337 -5.354 ... -8.861
scalarCanopyNetNrgFlux (time, hru) float64 -7.165 -7.193 ... -11.87
scalarGroundNetNrgFlux (time, hru) float64 -27.66 -27.68 ... -19.02
scalarLWNetUbound (time, hru) float64 -40.71 -40.77 ... -39.55
scalarSenHeatTotal (time, hru) float64 0.4441 0.4447 ... 3.267
scalarLatHeatTotal (time, hru) float64 -0.2061 ... -3.392
scalarLatHeatCanopyEvap (time, hru) float64 -0.1114 ... -2.079
scalarLatHeatCanopyTrans (time, hru) float64 -0.01746 ... -1.063
scalarLatHeatGround (time, hru) float64 -0.07726 ... -0.2504
scalarCanopySublimation (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarSnowSublimation (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarCanopyTranspiration (time, hru) float64 -6.98e-09 ... -4.248e-07
scalarCanopyEvaporation (time, hru) float64 -4.454e-08 ... -8.311...
scalarGroundEvaporation (time, hru) float64 -3.089e-08 ... -1.001...
scalarThroughfallSnow (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarThroughfallRain (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarCanopySnowUnloading_mean (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarRainPlusMelt (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarInfiltration (time, hru) float64 2.479e-14 ... 0.0
scalarExfiltration (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarSurfaceRunoff (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarSoilBaseflow (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarAquiferBaseflow (time, hru) float64 2.228e-11 ... 4.876e-09
scalarTotalRunoff (time, hru) float64 2.228e-11 ... 4.876e-09
scalarNetRadiation (time, hru) float64 -40.71 -40.77 ... -39.55
hruId (hru) int64 17006965 17006967 ... 17009664
averageInstantRunoff (time, gru) float64 4.448e-11 ... 9.744e-09
averageRoutedRunoff (time, gru) float64 4.459e-11 ... 9.92e-09
gruId (gru) int64 906922 906924 ... 909581 909583- gru: 285
- hru: 285
- ifcToto: 14
- midToto: 13
- time: 721
- hru(hru)int6417006965 17006967 ... 17009664
- long_name :
- hruId in the input file
- units :
- -
array([17006965, 17006967, 17006969, ..., 17009604, 17009662, 17009664])
- time(time)datetime64[ns]2010-06-01 ... 2010-07-01
- long_name :
- time since time reference (instant)
array(['2010-06-01T00:00:00.000000000', '2010-06-01T00:59:59.999986688', '2010-06-01T02:00:00.000013312', ..., '2010-06-30T21:59:59.999986688', '2010-06-30T23:00:00.000013312', '2010-07-01T00:00:00.000000000'], dtype='datetime64[ns]') - gru(gru)int64906922 906924 ... 909581 909583
- long_name :
- gruId in the input file
- units :
- -
array([906922, 906924, 906926, ..., 909523, 909581, 909583])
- pptrate(time, hru)float647.562e-05 7.606e-05 ... 1.418e-05
- long_name :
- precipitation rate (instant)
- units :
- kg m-2 s-1
array([[7.56163136e-05, 7.60601688e-05, 5.15421052e-05, ..., 5.12004772e-05, 7.64069482e-05, 6.71296293e-05], [7.56163136e-05, 7.60601688e-05, 5.15421052e-05, ..., 5.12004772e-05, 7.64069482e-05, 6.71296293e-05], [7.56163136e-05, 7.60601688e-05, 5.15421052e-05, ..., 5.12004772e-05, 7.64069482e-05, 6.71296293e-05], ..., [0.00000000e+00, 0.00000000e+00, 7.92784340e-06, ..., 2.89351846e-07, 9.61138994e-07, 8.68055565e-07], [0.00000000e+00, 0.00000000e+00, 7.92784340e-06, ..., 2.89351846e-07, 9.61138994e-07, 8.68055565e-07], [2.52938185e-06, 2.56903422e-06, 1.60732616e-05, ..., 1.76133108e-05, 1.61329936e-05, 1.41782411e-05]]) - airtemp(time, hru)float64279.2 279.1 287.9 ... 277.8 278.0
- long_name :
- air temperature at the measurement height (instant)
- units :
- K
array([[279.16464233, 279.10180664, 287.88330078, ..., 279.55426025, 277.30725098, 277.47616577], [277.83862305, 277.77490234, 286.64276123, ..., 278.72442627, 276.37030029, 276.52346802], [276.68637085, 276.62182617, 285.56466675, ..., 278.00335693, 275.55612183, 275.69558716], ..., [282.53366089, 282.48223877, 289.32037354, ..., 281.45050049, 279.69995117, 279.85458374], [280.41363525, 280.36248779, 287.4588623 , ..., 280.25997925, 278.4954834 , 278.64541626], [280.35980225, 280.31335449, 288.38198853, ..., 279.47991943, 277.83065796, 277.98855591]]) - windspd_mean(time, hru)float640.8894 0.8894 1.166 ... 1.265 1.266
- long_name :
- wind speed at the measurement height (mean)
- units :
- m s-1
array([[0.88942987, 0.8894136 , 1.16556144, ..., 1.46989083, 1.52078903, 1.52110004], [0.88942987, 0.8894136 , 1.16556144, ..., 1.46989083, 1.52078903, 1.52110004], [0.88942987, 0.8894136 , 1.16556144, ..., 1.46989083, 1.52078903, 1.52110004], ..., [2.54002619, 2.53933144, 2.87046552, ..., 2.1676178 , 2.15637445, 2.1572001 ], [2.54002619, 2.53933144, 2.87046552, ..., 2.1676178 , 2.15637445, 2.1572001 ], [1.60224426, 1.60180855, 1.77113569, ..., 1.29701996, 1.2652241 , 1.26619995]]) - SWRadAtm(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- downward shortwave radiation at the upper boundary (instant)
- units :
- W m-2
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - LWRadAtm(time, hru)float64287.4 287.1 333.5 ... 287.8 288.3
- long_name :
- downward longwave radiation at the upper boundary (instant)
- units :
- W m-2
array([[287.40258789, 287.07562256, 333.48782349, ..., 296.21936035, 282.74954224, 283.06121826], [282.04776001, 281.72177124, 327.86801147, ..., 292.76242065, 278.99124146, 279.23876953], [277.45541382, 277.13037109, 323.04211426, ..., 289.78302002, 275.75579834, 275.94857788], ..., [267.30368042, 267.06115723, 329.26171875, ..., 296.42745972, 288.24688721, 288.90286255], [259.50274658, 259.26660156, 321.00296021, ..., 291.51055908, 283.37393188, 284.00302124], [281.47229004, 281.27328491, 319.14331055, ..., 297.82312012, 287.81790161, 288.33462524]]) - scalarCanopyIce(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- mass of ice on the vegetation canopy (instant)
- units :
- kg m-2
array([[0. , 0. , 0. , ..., 0. , 0. , 0. ], [0. , 0. , 0. , ..., 0. , 0. , 0. ], [0. , 0. , 0. , ..., 0. , 0.02319168, 0.00730556], ..., [0. , 0. , 0. , ..., 0. , 0. , 0. ], [0. , 0. , 0. , ..., 0. , 0. , 0. ], [0. , 0. , 0. , ..., 0. , 0. , 0. ]]) - scalarCanopyLiq(time, hru)float640.2849 0.2866 ... 0.08693 0.07626
- long_name :
- mass of liquid water on the vegetation canopy (instant)
- units :
- kg m-2
array([[0.2848862 , 0.28661225, 0.35087317, ..., 0.25528067, 0.3613199 , 0.31721344], [0.55707802, 0.56040242, 0.54042229, ..., 0.44082329, 0.63726835, 0.55965798], [0.82944329, 0.83436647, 0.73040318, ..., 0.62767783, 0.89150277, 0.79635616], ..., [0.00523263, 0.00523645, 0.07405508, ..., 0.01060338, 0.03065529, 0.0269997 ], [0.00522588, 0.00522969, 0.09879395, ..., 0.01104933, 0.03200753, 0.02820905], [0.01282898, 0.01295744, 0.15836067, ..., 0.07099386, 0.08693351, 0.07625861]]) - scalarCanopyWat_mean(time, hru)float640.2849 0.2866 ... 0.08693 0.07626
- long_name :
- mass of total water on the vegetation canopy (mean)
- units :
- kg m-2
array([[0.2848862 , 0.28661225, 0.35087317, ..., 0.25528067, 0.3613199 , 0.31721344], [0.55707802, 0.56040242, 0.54042229, ..., 0.44082329, 0.63726835, 0.55965798], [0.82944329, 0.83436647, 0.73040318, ..., 0.62767783, 0.91469445, 0.80366172], ..., [0.00523263, 0.00523645, 0.07405508, ..., 0.01060338, 0.03065529, 0.0269997 ], [0.00522588, 0.00522969, 0.09879395, ..., 0.01104933, 0.03200753, 0.02820905], [0.01282898, 0.01295744, 0.15836067, ..., 0.07099386, 0.08693351, 0.07625861]]) - scalarCanairTemp(time, hru)float64275.7 275.6 282.1 ... 275.6 275.8
- long_name :
- temperature of the canopy air space (instant)
- units :
- K
array([[275.67493913, 275.61897099, 282.13812679, ..., 276.5496316 , 274.51310888, 274.63401125], [274.6583324 , 274.59992024, 281.88236478, ..., 275.86111914, 273.72431877, 273.82292771], [273.79851508, 273.73867956, 281.44635536, ..., 275.33920245, 273.25997274, 273.26301317], ..., [281.52671199, 281.47458662, 285.01133945, ..., 280.74910573, 278.95596146, 279.11499477], [279.53404011, 279.48192071, 283.28165643, ..., 279.5529211 , 277.74530593, 277.901004 ], [276.95616383, 276.90417864, 281.9011963 , ..., 277.4979156 , 275.61958526, 275.7662665 ]]) - scalarCanopyTemp(time, hru)float64275.6 275.5 282.1 ... 275.5 275.6
- long_name :
- temperature of the vegetation canopy (instant)
- units :
- K
array([[275.5898463 , 275.53362052, 282.10450556, ..., 276.44422027, 274.38967576, 274.51008951], [274.58872865, 274.53015735, 281.84347191, ..., 275.76600997, 273.61315019, 273.71158479], [273.7375521 , 273.67761803, 281.40141704, ..., 275.24874308, 273.15677422, 273.15808441], ..., [280.99633119, 280.94439876, 284.94327306, ..., 280.39597057, 278.60141797, 278.7604709 ], [279.03835098, 278.98636991, 283.20519399, ..., 279.21507167, 277.40745324, 277.56311727], [276.76309563, 276.71128983, 281.87593833, ..., 277.34612592, 275.47096086, 275.61721434]]) - scalarSnowAlbedo(time, hru)float64-9.999e+03 ... -9.999e+03
- long_name :
- snow albedo for the entire spectral band (instant)
- units :
- -
array([[-9999., -9999., -9999., ..., -9999., -9999., -9999.], [-9999., -9999., -9999., ..., -9999., -9999., -9999.], [-9999., -9999., -9999., ..., -9999., -9999., -9999.], ..., [-9999., -9999., -9999., ..., -9999., -9999., -9999.], [-9999., -9999., -9999., ..., -9999., -9999., -9999.], [-9999., -9999., -9999., ..., -9999., -9999., -9999.]]) - scalarSnowDepth_mean(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- total snow depth (mean)
- units :
- m
array([[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [5.95065803e-10, 6.71683864e-10, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]) - scalarSWE(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- snow water equivalent (instant)
- units :
- kg m-2
array([[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [8.92598704e-08, 1.00752580e-07, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]) - mLayerTemp_mean(time, midToto, hru)float64281.0 281.0 ... -9.999e+03
- long_name :
- temperature of each layer (mean)
- units :
- K
array([[[ 281.01348304, 280.96274488, 286.23043799, ..., 280.43873073, 278.69752846, 278.84283714], [ 281.73704322, 281.68621174, 287.23176891, ..., 280.96916059, 279.25721178, 279.40621677], [ 281.87887428, 281.82764699, 287.87448249, ..., 281.11595109, 279.42198287, 279.57182636], ..., [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ]], [[ 280.54024602, 280.48915431, 285.81529782, ..., 280.09974108, 278.33034657, 278.4705361 ], [ 281.36612715, 281.31522321, 286.8483686 , ..., 280.7094432 , 278.98149345, 279.12766476], [ 281.78925887, 281.73810036, 287.74284 , ..., 281.05507782, 279.35631722, 279.50560905], ... [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ]], [[ 281.50267905, 281.45215995, 286.81199433, ..., 280.80265241, 279.08511166, 279.23546735], [ 282.10756768, 282.0563797 , 287.8339394 , ..., 281.21854807, 279.51019407, 279.66207391], [ 281.92149854, 281.86973562, 288.18195298, ..., 281.13592528, 279.43489511, 279.58600375], ..., [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ]]]) - scalarSurfaceTemp(time, hru)float64281.0 281.0 286.2 ... 279.1 279.2
- long_name :
- surface temperature (just a copy of the upper-layer temperature) (instant)
- units :
- K
array([[281.01348304, 280.96274488, 286.23043799, ..., 280.43873073, 278.69752846, 278.84283714], [280.54024602, 280.48915431, 285.81529782, ..., 280.09974108, 278.33034657, 278.4705361 ], [280.09935275, 280.04798328, 285.40362561, ..., 279.79539676, 278.01405943, 278.1405834 ], ..., [282.78789386, 282.73631115, 288.34826687, ..., 281.63185555, 279.92142551, 280.07575016], [282.09769348, 282.04672115, 287.39572212, ..., 281.23163826, 279.52051871, 279.67307917], [281.50267905, 281.45215995, 286.81199433, ..., 280.80265241, 279.08511166, 279.23546735]]) - mLayerDepth_mean(time, midToto, hru)float640.025 0.025 ... -9.999e+03
- long_name :
- depth of each layer (mean)
- units :
- m
array([[[ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 7.500e-02, 7.500e-02, 7.500e-02, ..., 7.500e-02, 7.500e-02, 7.500e-02], [ 1.500e-01, 1.500e-01, 1.500e-01, ..., 1.500e-01, 1.500e-01, 1.500e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 7.500e-02, 7.500e-02, 7.500e-02, ..., 7.500e-02, 7.500e-02, 7.500e-02], [ 1.500e-01, 1.500e-01, 1.500e-01, ..., 1.500e-01, 1.500e-01, 1.500e-01], ... [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 7.500e-02, 7.500e-02, 7.500e-02, ..., 7.500e-02, 7.500e-02, 7.500e-02], [ 1.500e-01, 1.500e-01, 1.500e-01, ..., 1.500e-01, 1.500e-01, 1.500e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]]]) - mLayerHeight_mean(time, midToto, hru)float640.0125 0.0125 ... -9.999e+03
- long_name :
- height of the layer mid-point (top of soil = 0) (mean)
- units :
- m
array([[[ 1.250e-02, 1.250e-02, 1.250e-02, ..., 1.250e-02, 1.250e-02, 1.250e-02], [ 6.250e-02, 6.250e-02, 6.250e-02, ..., 6.250e-02, 6.250e-02, 6.250e-02], [ 1.750e-01, 1.750e-01, 1.750e-01, ..., 1.750e-01, 1.750e-01, 1.750e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[ 1.250e-02, 1.250e-02, 1.250e-02, ..., 1.250e-02, 1.250e-02, 1.250e-02], [ 6.250e-02, 6.250e-02, 6.250e-02, ..., 6.250e-02, 6.250e-02, 6.250e-02], [ 1.750e-01, 1.750e-01, 1.750e-01, ..., 1.750e-01, 1.750e-01, 1.750e-01], ... [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[ 1.250e-02, 1.250e-02, 1.250e-02, ..., 1.250e-02, 1.250e-02, 1.250e-02], [ 6.250e-02, 6.250e-02, 6.250e-02, ..., 6.250e-02, 6.250e-02, 6.250e-02], [ 1.750e-01, 1.750e-01, 1.750e-01, ..., 1.750e-01, 1.750e-01, 1.750e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]]]) - iLayerHeight_mean(time, ifcToto, hru)float64-0.0 -0.0 ... -9.999e+03 -9.999e+03
- long_name :
- height of the layer interface (top of soil = 0) (mean)
- units :
- m
array([[[-0.000e+00, -0.000e+00, -0.000e+00, ..., -0.000e+00, -0.000e+00, -0.000e+00], [ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 1.000e-01, 1.000e-01, 1.000e-01, ..., 1.000e-01, 1.000e-01, 1.000e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[-0.000e+00, -0.000e+00, -0.000e+00, ..., -0.000e+00, -0.000e+00, -0.000e+00], [ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 1.000e-01, 1.000e-01, 1.000e-01, ..., 1.000e-01, 1.000e-01, 1.000e-01], ... [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[-0.000e+00, -0.000e+00, -0.000e+00, ..., -0.000e+00, -0.000e+00, -0.000e+00], [ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 1.000e-01, 1.000e-01, 1.000e-01, ..., 1.000e-01, 1.000e-01, 1.000e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]]]) - scalarTotalSoilLiq(time, hru)float641.169e+03 1.172e+03 ... 1.273e+03
- long_name :
- total mass of liquid water in the soil (instant)
- units :
- kg m-2
array([[1169.4861494 , 1171.95923543, 958.16016633, ..., 1273.18576626, 1275.53986186, 1272.82216379], [1169.48593486, 1171.95901743, 958.15606966, ..., 1273.16738024, 1275.51940637, 1272.80433547], [1169.48570129, 1171.95878033, 958.15155395, ..., 1273.14902732, 1275.4989666 , 1272.78651745], ..., [1160.41594809, 1163.19740491, 934.31440308, ..., 1273.25450403, 1275.61803344, 1272.8950666 ], [1160.40710502, 1163.18858504, 934.30586475, ..., 1273.23245505, 1275.5942375 , 1272.87383523], [1160.40161177, 1163.18311216, 934.30247678, ..., 1273.21199869, 1275.57230158, 1272.85442138]]) - scalarTotalSoilIce(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- total mass of ice in the soil (instant)
- units :
- kg m-2
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarCanairNetNrgFlux(time, hru)float64-5.337 -5.354 ... -8.824 -8.861
- long_name :
- net energy flux for the canopy air space (instant)
- units :
- W m-2
array([[ -5.33665068, -5.35352425, 0.05145734, ..., -3.95640942, -4.62416228, -4.73023102], [ -4.22000441, -4.2301497 , -0.04154422, ..., -2.85806254, -3.27432198, -3.36686352], [ -3.56916084, -3.57506927, -0.07082237, ..., -2.1665121 , -1.92753229, -2.32424376], ..., [-10.83225207, -10.83626063, -0.48038826, ..., -6.76362156, -6.9601605 , -6.95940903], [ -8.27172309, -8.27169831, -0.28095782, ..., -4.96582636, -5.02593892, -5.03980611], [-10.70094166, -10.70038454, -0.22423245, ..., -8.53046911, -8.82401264, -8.86144212]]) - scalarCanopyNetNrgFlux(time, hru)float64-7.165 -7.193 ... -11.83 -11.87
- long_name :
- net energy flux for the vegetation canopy (instant)
- units :
- W m-2
array([[ -7.16526191, -7.19282902, 1.92615247, ..., -5.57814736, -6.71831698, -6.86256314], [ -6.40746141, -6.42448501, -1.6907005 , ..., -4.31743565, -5.03893454, -5.1406557 ], [ -5.71686661, -5.72931113, -2.96047905, ..., -3.40434639, -5.2589829 , -4.39825206], ..., [-16.54630604, -16.55311868, -18.18739624, ..., -10.65658065, -10.96970299, -10.95864699], [-11.895751 , -11.89605518, -10.6986609 , ..., -7.18194346, -7.2892121 , -7.30481812], [-13.48716293, -13.46511197, -8.22035976, ..., -11.36744576, -11.82541851, -11.87430079]]) - scalarGroundNetNrgFlux(time, hru)float64-27.66 -27.68 ... -18.96 -19.02
- long_name :
- net energy flux for the ground surface (instant)
- units :
- W m-2
array([[-27.6617224 , -27.67563288, -31.05321773, ..., -20.93508828, -22.27298511, -22.42966287], [-30.0221631 , -30.04327782, -31.50906674, ..., -22.51597493, -24.14809286, -24.38020319], [-31.81858976, -31.84314524, -32.78135098, ..., -23.51288278, -24.842537 , -25.42867012], ..., [-14.68521427, -14.67404115, -31.16969028, ..., -9.17460693, -9.40513528, -9.41526243], [-22.02694495, -22.01279323, -36.67175578, ..., -13.34320421, -13.53238615, -13.56492797], [-25.86526886, -25.85248614, -33.17731067, ..., -18.58323122, -18.95967152, -19.02203735]]) - scalarLWNetUbound(time, hru)float64-40.71 -40.77 ... -39.37 -39.55
- long_name :
- net longwave radiation at the upper atmospheric boundary (instant)
- units :
- W m-2
array([[-40.7119976 , -40.77255112, -29.56254598, ..., -35.70264643, -39.47904496, -39.73771877], [-41.43011564, -41.48187658, -33.68592205, ..., -35.98100097, -39.6841971 , -39.90304466], [-42.11204292, -42.1592099 , -36.27644994, ..., -36.54286069, -40.82637954, -40.6631726 ], ..., [-86.56497836, -86.54610288, -46.09317066, ..., -54.32188429, -53.62624578, -53.75060794], [-84.84958573, -84.82951129, -45.64387655, ..., -53.51608015, -52.82481146, -52.95017138], [-52.10863573, -52.05836084, -41.01446837, ..., -38.33150601, -39.37095617, -39.55003625]]) - scalarSenHeatTotal(time, hru)float640.4441 0.4447 ... 3.265 3.267
- long_name :
- sensible heat from the canopy air space to the atmosphere (instant)
- units :
- W m-2
array([[ 0.44411986, 0.44468515, 0.11072185, ..., 5.15839293, 6.21129545, 6.15150459], [ 0.47860871, 0.47907692, 0.12996642, ..., 5.31007931, 6.40581411, 6.33080321], [ 0.51754829, 0.51802478, 0.14645162, ..., 5.55707042, 6.9818517 , 6.74439461], ..., [50.72431645, 50.68940054, 6.55259368, ..., 31.12284583, 30.96579041, 30.9723003 ], [48.76206028, 48.73818752, 6.56791198, ..., 31.08201682, 30.91102234, 30.90741575], [ 6.9032337 , 6.88520143, 0.66789982, ..., 3.96197726, 3.26461065, 3.2671361 ]]) - scalarLatHeatTotal(time, hru)float64-0.2061 -0.2063 ... -3.415 -3.392
- long_name :
- latent heat from the canopy air space to the atmosphere (instant)
- units :
- W m-2
array([[-2.06107360e-01, -2.06276121e-01, -3.38701350e-02, ..., -2.42349205e-01, -7.60195704e-01, -7.97535232e-01], [-1.12236512e-01, -1.11969883e-01, -3.69461340e-02, ..., 6.04657124e-01, 3.11418266e-01, 2.37182844e-01], [-4.98399297e-03, -4.46892466e-03, -2.81129545e-02, ..., 1.49331460e+00, 1.30049622e+00, 1.28653661e+00], ..., [-6.22311047e+00, -6.20671813e+00, -1.02372882e+01, ..., -3.39333648e+00, -4.66706950e+00, -4.54806218e+00], [-6.10689359e+00, -6.08922296e+00, -8.54602503e+00, ..., -3.05520452e+00, -3.92863922e+00, -3.86199258e+00], [-4.81910825e+00, -4.81596960e+00, -1.14393032e+00, ..., -3.99021763e+00, -3.41458641e+00, -3.39159389e+00]]) - scalarLatHeatCanopyEvap(time, hru)float64-0.1114 -0.1116 ... -2.19 -2.079
- long_name :
- evaporation latent heat from the canopy to the canopy air space (instant)
- units :
- W m-2
array([[-0.11138575, -0.11155042, 2.53971121, ..., -0.01823886, -0.44549586, -0.47221855], [-0.01869067, -0.0183685 , 2.75904364, ..., 0.78904184, 0.58381453, 0.51035764], [ 0.09697385, 0.09759279, 3.06324936, ..., 1.6737568 , 1.58429569, 1.56114712], ..., [-0.00619367, -0.00620172, -4.38979927, ..., -0.46854264, -1.91010885, -1.72613427], [-0.00469088, -0.00469568, -2.64089253, ..., -0.41386125, -1.46437811, -1.33084503], [-1.04388356, -1.05644678, 1.13896614, ..., -2.40609233, -2.19031967, -2.07868264]]) - scalarLatHeatCanopyTrans(time, hru)float64-0.01746 -0.01739 ... -1.063
- long_name :
- transpiration latent heat from the canopy to the canopy air space (instant)
- units :
- W m-2
array([[-1.74575918e-02, -1.73872409e-02, 2.74845684e-02, ..., -2.42216841e-03, -4.18324180e-02, -5.07091396e-02], [-1.44201745e-03, -1.40919656e-03, 1.81410577e-02, ..., 5.91467664e-02, 2.99288471e-02, 3.00441578e-02], [ 4.83327931e-03, 4.83584456e-03, 1.38920331e-02, ..., 8.58521767e-02, 5.60135036e-02, 6.24776902e-02], ..., [-3.93704858e+00, -3.92792251e+00, -2.91023598e-01, ..., -2.00490525e+00, -1.88679749e+00, -1.93359682e+00], [-2.98695972e+00, -2.97925440e+00, -1.29880304e-01, ..., -1.47757427e+00, -1.38022181e+00, -1.42155294e+00], [-3.01589274e+00, -3.00427284e+00, 4.41336281e-02, ..., -1.26607792e+00, -9.82665496e-01, -1.06253808e+00]]) - scalarLatHeatGround(time, hru)float64-0.07726 -0.07734 ... -0.2504
- long_name :
- latent heat from the ground (below canopy or non-vegetated) (instant)
- units :
- W m-2
array([[-0.07726401, -0.07733846, -2.60106591, ..., -0.22168818, -0.27286743, -0.27460755], [-0.09210382, -0.09219219, -2.81413083, ..., -0.24353148, -0.30232511, -0.30321896], [-0.10679112, -0.10689756, -3.10525435, ..., -0.26629438, -0.33981297, -0.3370882 ], ..., [-2.27986822, -2.27259389, -5.55646537, ..., -0.91988859, -0.87016316, -0.88833109], [-3.11524299, -3.10527288, -5.7752522 , ..., -1.163769 , -1.08403931, -1.1095946 ], [-0.75933195, -0.75524998, -2.32703009, ..., -0.31804738, -0.24160124, -0.25037317]]) - scalarCanopySublimation(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- canopy sublimation/frost (instant)
- units :
- kg m-2 s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarSnowSublimation(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- snow sublimation/frost (below canopy or non-vegetated) (instant)
- units :
- kg m-2 s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarCanopyTranspiration(time, hru)float64-6.98e-09 -6.952e-09 ... -4.248e-07
- long_name :
- canopy transpiration (instant)
- units :
- kg m-2 s-1
array([[-6.98024461e-09, -6.95211551e-09, 0.00000000e+00, ..., -9.68479974e-10, -1.67262767e-08, -2.02755456e-08], [-5.76576348e-10, -5.63453245e-10, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [-1.57418976e-06, -1.57054079e-06, -1.16362894e-07, ..., -8.01641444e-07, -7.54417230e-07, -7.73129476e-07], [-1.19430617e-06, -1.19122527e-06, -5.19313490e-08, ..., -5.90793389e-07, -5.51867977e-07, -5.68393818e-07], [-1.20587475e-06, -1.20122864e-06, 0.00000000e+00, ..., -5.06228676e-07, -3.92909035e-07, -4.24845293e-07]]) - scalarCanopyEvaporation(time, hru)float64-4.454e-08 -4.46e-08 ... -8.311e-07
- long_name :
- canopy evaporation/condensation (instant)
- units :
- kg m-2 s-1
array([[-4.45364868e-08, -4.46023283e-08, 1.02646772e-06, ..., -7.29262585e-09, -1.78127093e-07, -1.88811894e-07], [-7.47327902e-09, -7.34446246e-09, 1.11042971e-06, ..., 3.39139787e-07, 2.45399190e-07, 2.16074291e-07], [ 4.07065672e-08, 4.09550726e-08, 1.23036441e-06, ..., 7.03562167e-07, 6.55861332e-07, 6.49190248e-07], ..., [-2.47647636e-09, -2.47969791e-09, -1.75521762e-06, ..., -1.87342119e-07, -7.63738046e-07, -6.90177636e-07], [-1.87560111e-09, -1.87752208e-09, -1.05593464e-06, ..., -1.65478309e-07, -5.85517036e-07, -5.32125163e-07], [-4.17386470e-07, -4.22409750e-07, 4.73050685e-07, ..., -9.62052110e-07, -8.75777557e-07, -8.31140599e-07]]) - scalarGroundEvaporation(time, hru)float64-3.089e-08 ... -1.001e-07
- long_name :
- ground evaporation/condensation (below canopy or non-vegetated) (instant)
- units :
- kg m-2 s-1
array([[-3.08932487e-08, -3.09230134e-08, -1.04001036e-06, ..., -8.86398160e-08, -1.09103329e-07, -1.09799099e-07], [-3.68267990e-08, -3.68621294e-08, -1.12520225e-06, ..., -9.73736442e-08, -1.20881691e-07, -1.21239088e-07], [-4.26993673e-08, -4.27419277e-08, -1.24160510e-06, ..., -1.06475160e-07, -1.35870839e-07, -1.34781368e-07], ..., [-9.11582656e-07, -9.08674088e-07, -2.22169747e-06, ..., -3.67808311e-07, -3.47926093e-07, -3.55190359e-07], [-1.24559896e-06, -1.24161250e-06, -2.30917721e-06, ..., -4.65321472e-07, -4.33442346e-07, -4.43660378e-07], [-3.03611334e-07, -3.01979199e-07, -9.30439859e-07, ..., -1.27168086e-07, -9.66018551e-08, -1.00109225e-07]]) - scalarThroughfallSnow(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- snow that reaches the ground without ever touching the canopy (instant)
- units :
- kg m-2 s-1
array([[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [2.47944085e-11, 2.79868277e-11, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]) - scalarThroughfallRain(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- rain that reaches the ground without ever touching the canopy (instant)
- units :
- kg m-2 s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarCanopySnowUnloading_mean(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- unloading of snow from the vegetation canopy (mean)
- units :
- kg m-2 s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarRainPlusMelt(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- rain plus melt, used as input to soil before surface runoff (instant)
- units :
- m s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarInfiltration(time, hru)float642.479e-14 2.799e-14 0.0 ... 0.0 0.0
- long_name :
- infiltration of water into the soil profile (instant)
- units :
- m s-1
array([[2.47944085e-14, 2.79868277e-14, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]) - scalarExfiltration(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- exfiltration of water from the top of the soil profile (instant)
- units :
- m s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarSurfaceRunoff(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- surface runoff (instant)
- units :
- m s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarSoilBaseflow(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- total baseflow from the soil profile (instant)
- units :
- m s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarAquiferBaseflow(time, hru)float642.228e-11 2.322e-11 ... 4.876e-09
- long_name :
- baseflow from the aquifer (instant)
- units :
- m s-1
array([[2.22791761e-11, 2.32214883e-11, 1.25935985e-11, ..., 5.03750135e-09, 5.58997037e-09, 4.85598286e-09], [2.22685802e-11, 2.32103178e-11, 1.25902365e-11, ..., 5.01888132e-09, 5.57026701e-09, 4.83930571e-09], [2.22579922e-11, 2.31991558e-11, 1.25868743e-11, ..., 5.00048979e-09, 5.55081344e-09, 4.82282242e-09], ..., [1.64822147e-11, 1.71062142e-11, 1.03332838e-11, ..., 5.09654926e-09, 5.65375134e-09, 4.91053191e-09], [1.64758234e-11, 1.70994585e-11, 1.03299416e-11, ..., 5.07723255e-09, 5.63328546e-09, 4.89326018e-09], [1.64694358e-11, 1.70927066e-11, 1.03265985e-11, ..., 5.05814454e-09, 5.61306857e-09, 4.87618136e-09]]) - scalarTotalRunoff(time, hru)float642.228e-11 2.322e-11 ... 4.876e-09
- long_name :
- total runoff (instant)
- units :
- m s-1
array([[2.22791761e-11, 2.32214883e-11, 1.25935985e-11, ..., 5.03750135e-09, 5.58997037e-09, 4.85598286e-09], [2.22685802e-11, 2.32103178e-11, 1.25902365e-11, ..., 5.01888132e-09, 5.57026701e-09, 4.83930571e-09], [2.22579922e-11, 2.31991558e-11, 1.25868743e-11, ..., 5.00048979e-09, 5.55081344e-09, 4.82282242e-09], ..., [1.64822147e-11, 1.71062142e-11, 1.03332838e-11, ..., 5.09654926e-09, 5.65375134e-09, 4.91053191e-09], [1.64758234e-11, 1.70994585e-11, 1.03299416e-11, ..., 5.07723255e-09, 5.63328546e-09, 4.89326018e-09], [1.64694358e-11, 1.70927066e-11, 1.03265985e-11, ..., 5.05814454e-09, 5.61306857e-09, 4.87618136e-09]]) - scalarNetRadiation(time, hru)float64-40.71 -40.77 ... -39.37 -39.55
- long_name :
- net radiation (instant)
- units :
- W m-2
array([[-40.7119976 , -40.77255112, -29.56254598, ..., -35.70264643, -39.47904496, -39.73771877], [-41.43011564, -41.48187658, -33.68592205, ..., -35.98100097, -39.6841971 , -39.90304466], [-42.11204292, -42.1592099 , -36.27644994, ..., -36.54286069, -40.82637954, -40.6631726 ], ..., [-86.56497836, -86.54610288, -46.09317066, ..., -54.32188429, -53.62624578, -53.75060794], [-84.84958573, -84.82951129, -45.64387655, ..., -53.51608015, -52.82481146, -52.95017138], [-52.10863573, -52.05836084, -41.01446837, ..., -38.33150601, -39.37095617, -39.55003625]]) - hruId(hru)int6417006965 17006967 ... 17009664
- long_name :
- ID defining the hydrologic response unit
- units :
- -
array([17006965, 17006967, 17006969, 17006970, 17006971, 17006972, 17006973, 17006974, 17006976, 17006978, 17006979, 17006980, 17006982, 17006984, 17006985, 17006986, 17006987, 17006988, 17006989, 17006990, 17006991, 17006992, 17006993, 17006994, 17006995, 17006996, 17006997, 17006998, 17006999, 17007000, 17007001, 17007002, 17007003, 17007004, 17007005, 17007007, 17007008, 17007013, 17007014, 17007016, 17007017, 17007018, 17007020, 17007021, 17007022, 17007023, 17007024, 17007025, 17007026, 17007030, 17007031, 17007032, 17007033, 17007034, 17007035, 17007036, 17007037, 17007038, 17007039, 17007040, 17007041, 17007042, 17007043, 17007044, 17007045, 17007046, 17007047, 17007048, 17007049, 17007050, 17007052, 17007053, 17007055, 17007057, 17007058, 17007059, 17007060, 17007061, 17007062, 17007063, 17007064, 17007065, 17007067, 17007068, 17007069, 17007070, 17007072, 17007073, 17007074, 17007075, 17007076, 17007079, 17007080, 17007081, 17007082, 17007083, 17007085, 17007088, 17007090, 17007092, 17007097, 17007098, 17007105, 17007106, 17007107, 17007108, 17007111, 17007112, 17007118, 17007119, 17007125, 17007126, 17007127, 17007129, 17007131, 17007132, 17007134, 17007135, 17007137, 17007139, ... 17007255, 17007257, 17007258, 17007261, 17007265, 17007270, 17007272, 17007280, 17007282, 17007287, 17007291, 17007299, 17007308, 17007309, 17007313, 17007318, 17007321, 17007322, 17007323, 17007327, 17007328, 17007330, 17007337, 17007341, 17007344, 17007346, 17007350, 17007366, 17007367, 17007376, 17007389, 17007390, 17007391, 17007394, 17007397, 17007398, 17007401, 17007402, 17007404, 17007408, 17007415, 17007425, 17007427, 17007433, 17007440, 17007466, 17007468, 17007474, 17007491, 17007492, 17007494, 17007518, 17007534, 17007557, 17007576, 17007611, 17007640, 17007647, 17007670, 17007677, 17007679, 17007727, 17007729, 17007755, 17007759, 17007760, 17007763, 17007768, 17009407, 17009416, 17009418, 17009420, 17009421, 17009423, 17009424, 17009425, 17009426, 17009427, 17009433, 17009434, 17009435, 17009436, 17009437, 17009438, 17009501, 17009502, 17009505, 17009506, 17009508, 17009509, 17009510, 17009511, 17009512, 17009513, 17009518, 17009519, 17009524, 17009531, 17009532, 17009537, 17009538, 17009541, 17009542, 17009547, 17009550, 17009567, 17009568, 17009569, 17009570, 17009581, 17009582, 17009595, 17009596, 17009603, 17009604, 17009662, 17009664]) - averageInstantRunoff(time, gru)float644.448e-11 4.636e-11 ... 9.744e-09
- long_name :
- instantaneous runoff (instant)
- units :
- m s-1
array([[4.44811433e-11, 4.63632503e-11, 2.51546387e-11, ..., 1.00658819e-08, 1.11707745e-08, 9.70365019e-09], [4.44599878e-11, 4.63409467e-11, 2.51479061e-11, ..., 1.00287367e-08, 1.11314675e-08, 9.67037805e-09], [4.44388514e-11, 4.63186631e-11, 2.51411757e-11, ..., 9.99204790e-09, 1.10926596e-08, 9.63749324e-09], ..., [3.29102927e-11, 3.41562588e-11, 2.06308432e-11, ..., 1.01836988e-08, 1.12980446e-08, 9.81250712e-09], [3.28975285e-11, 3.41427658e-11, 2.06241411e-11, ..., 1.01451557e-08, 1.12572067e-08, 9.77804088e-09], [3.28847740e-11, 3.41292831e-11, 2.06174413e-11, ..., 1.01070724e-08, 1.12168700e-08, 9.74396312e-09]]) - averageRoutedRunoff(time, gru)float644.459e-11 4.648e-11 ... 9.92e-09
- long_name :
- routed runoff (instant)
- units :
- m s-1
array([[4.45884281e-11, 4.64763557e-11, 2.51886770e-11, ..., 1.02618630e-08, 1.13781799e-08, 9.87866192e-09], [4.45671958e-11, 4.64539716e-11, 2.51819454e-11, ..., 1.02228841e-08, 1.13369436e-08, 9.84387415e-09], [4.45459776e-11, 4.64316023e-11, 2.51752129e-11, ..., 1.01842288e-08, 1.12960410e-08, 9.80935063e-09], ..., [3.29749715e-11, 3.42246281e-11, 2.06646899e-11, ..., 1.03839193e-08, 1.15097191e-08, 9.99097777e-09], [3.29621732e-11, 3.42110995e-11, 2.06579984e-11, ..., 1.03442629e-08, 1.14678334e-08, 9.95565040e-09], [3.29493809e-11, 3.41975774e-11, 2.06513039e-11, ..., 1.03047681e-08, 1.14260844e-08, 9.92044113e-09]]) - gruId(gru)int64906922 906924 ... 909581 909583
- long_name :
- ID defining the grouped (basin) response unit
- units :
- -
array([906922, 906924, 906926, 906927, 906928, 906929, 906930, 906931, 906933, 906935, 906936, 906937, 906939, 906941, 906942, 906943, 906944, 906945, 906946, 906947, 906948, 906949, 906950, 906951, 906952, 906953, 906954, 906955, 906956, 906957, 906958, 906959, 906960, 906961, 906962, 906964, 906965, 906970, 906971, 906973, 906974, 906975, 906977, 906978, 906979, 906980, 906981, 906982, 906983, 906987, 906988, 906989, 906990, 906991, 906992, 906993, 906994, 906995, 906996, 906997, 906998, 906999, 907000, 907001, 907002, 907003, 907004, 907005, 907006, 907007, 907009, 907010, 907012, 907014, 907015, 907016, 907017, 907018, 907019, 907020, 907021, 907022, 907024, 907025, 907026, 907027, 907029, 907030, 907031, 907032, 907033, 907036, 907037, 907038, 907039, 907040, 907042, 907045, 907047, 907049, 907054, 907055, 907062, 907063, 907064, 907065, 907068, 907069, 907075, 907076, 907082, 907083, 907084, 907086, 907088, 907089, 907091, 907092, 907094, 907096, 907098, 907099, 907100, 907101, 907104, 907107, 907110, 907113, 907114, 907115, 907118, 907121, 907123, 907125, 907126, 907127, 907128, 907130, 907131, 907132, 907134, 907135, 907136, 907139, 907142, 907143, 907147, 907149, 907156, 907163, 907166, 907168, 907170, 907184, 907185, 907186, 907188, 907190, 907193, 907194, 907198, 907200, 907201, 907202, 907206, 907207, 907209, 907211, 907212, 907214, 907215, 907218, 907222, 907227, 907229, 907237, 907239, 907244, 907248, 907256, 907265, 907266, 907270, 907275, 907278, 907279, 907280, 907284, 907285, 907287, 907294, 907298, 907301, 907303, 907307, 907323, 907324, 907333, 907346, 907347, 907348, 907351, 907354, 907355, 907358, 907359, 907361, 907365, 907372, 907382, 907384, 907390, 907397, 907423, 907425, 907431, 907448, 907449, 907451, 907475, 907491, 907514, 907533, 907568, 907597, 907604, 907627, 907634, 907636, 907684, 907686, 907712, 907716, 907717, 907720, 907725, 909326, 909335, 909337, 909339, 909340, 909342, 909343, 909344, 909345, 909346, 909352, 909353, 909354, 909355, 909356, 909357, 909420, 909421, 909424, 909425, 909427, 909428, 909429, 909430, 909431, 909432, 909437, 909438, 909443, 909450, 909451, 909456, 909457, 909460, 909461, 909466, 909469, 909486, 909487, 909488, 909489, 909500, 909501, 909514, 909515, 909522, 909523, 909581, 909583])
Basic visualization¶
Once we have run a successful simulation you might note that the gru dimension doesn’t contain any geometry data on which we can actually draw our output. To do that we will use the associated shapefile, loaded in via GeoPandas, and plot the mean surface temperature via the psp.spatial functionality. For more information on the spatial plotting capabilities see the plotting page in the documentation. Here we plot the traces
of the input precipitation rate and total soil moisture timeseries for each of the HRU as well as a spatial plot showing the mean soil moisture over the simulation period.
[5]:
yakima_ds
[5]:
<xarray.Dataset>
Dimensions: (gru: 285, hru: 285, ifcToto: 14, midToto: 13, time: 721)
Coordinates:
* hru (hru) int64 17006965 17006967 ... 17009664
* time (time) datetime64[ns] 2010-06-01 ... 2010...
* gru (gru) int64 906922 906924 ... 909581 909583
Dimensions without coordinates: ifcToto, midToto
Data variables:
pptrate (time, hru) float64 7.562e-05 ... 1.418e-05
airtemp (time, hru) float64 279.2 279.1 ... 278.0
windspd_mean (time, hru) float64 0.8894 0.8894 ... 1.266
SWRadAtm (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
LWRadAtm (time, hru) float64 287.4 287.1 ... 288.3
scalarCanopyIce (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarCanopyLiq (time, hru) float64 0.2849 ... 0.07626
scalarCanopyWat_mean (time, hru) float64 0.2849 ... 0.07626
scalarCanairTemp (time, hru) float64 275.7 275.6 ... 275.8
scalarCanopyTemp (time, hru) float64 275.6 275.5 ... 275.6
scalarSnowAlbedo (time, hru) float64 -9.999e+03 ... -9.999...
scalarSnowDepth_mean (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarSWE (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
mLayerTemp_mean (time, midToto, hru) float64 281.0 ... -9...
scalarSurfaceTemp (time, hru) float64 281.0 281.0 ... 279.2
mLayerDepth_mean (time, midToto, hru) float64 0.025 ... -9...
mLayerHeight_mean (time, midToto, hru) float64 0.0125 ... -...
iLayerHeight_mean (time, ifcToto, hru) float64 -0.0 ... -9....
scalarTotalSoilLiq (time, hru) float64 1.169e+03 ... 1.273e+03
scalarTotalSoilIce (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarCanairNetNrgFlux (time, hru) float64 -5.337 -5.354 ... -8.861
scalarCanopyNetNrgFlux (time, hru) float64 -7.165 -7.193 ... -11.87
scalarGroundNetNrgFlux (time, hru) float64 -27.66 -27.68 ... -19.02
scalarLWNetUbound (time, hru) float64 -40.71 -40.77 ... -39.55
scalarSenHeatTotal (time, hru) float64 0.4441 0.4447 ... 3.267
scalarLatHeatTotal (time, hru) float64 -0.2061 ... -3.392
scalarLatHeatCanopyEvap (time, hru) float64 -0.1114 ... -2.079
scalarLatHeatCanopyTrans (time, hru) float64 -0.01746 ... -1.063
scalarLatHeatGround (time, hru) float64 -0.07726 ... -0.2504
scalarCanopySublimation (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarSnowSublimation (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarCanopyTranspiration (time, hru) float64 -6.98e-09 ... -4.248e-07
scalarCanopyEvaporation (time, hru) float64 -4.454e-08 ... -8.311...
scalarGroundEvaporation (time, hru) float64 -3.089e-08 ... -1.001...
scalarThroughfallSnow (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarThroughfallRain (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarCanopySnowUnloading_mean (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarRainPlusMelt (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarInfiltration (time, hru) float64 2.479e-14 ... 0.0
scalarExfiltration (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarSurfaceRunoff (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarSoilBaseflow (time, hru) float64 0.0 0.0 0.0 ... 0.0 0.0
scalarAquiferBaseflow (time, hru) float64 2.228e-11 ... 4.876e-09
scalarTotalRunoff (time, hru) float64 2.228e-11 ... 4.876e-09
scalarNetRadiation (time, hru) float64 -40.71 -40.77 ... -39.55
hruId (hru) int64 17006965 17006967 ... 17009664
averageInstantRunoff (time, gru) float64 4.448e-11 ... 9.744e-09
averageRoutedRunoff (time, gru) float64 4.459e-11 ... 9.92e-09
gruId (gru) int64 906922 906924 ... 909581 909583- gru: 285
- hru: 285
- ifcToto: 14
- midToto: 13
- time: 721
- hru(hru)int6417006965 17006967 ... 17009664
- long_name :
- hruId in the input file
- units :
- -
array([17006965, 17006967, 17006969, ..., 17009604, 17009662, 17009664])
- time(time)datetime64[ns]2010-06-01 ... 2010-07-01
- long_name :
- time since time reference (instant)
array(['2010-06-01T00:00:00.000000000', '2010-06-01T00:59:59.999986688', '2010-06-01T02:00:00.000013312', ..., '2010-06-30T21:59:59.999986688', '2010-06-30T23:00:00.000013312', '2010-07-01T00:00:00.000000000'], dtype='datetime64[ns]') - gru(gru)int64906922 906924 ... 909581 909583
- long_name :
- gruId in the input file
- units :
- -
array([906922, 906924, 906926, ..., 909523, 909581, 909583])
- pptrate(time, hru)float647.562e-05 7.606e-05 ... 1.418e-05
- long_name :
- precipitation rate (instant)
- units :
- kg m-2 s-1
array([[7.56163136e-05, 7.60601688e-05, 5.15421052e-05, ..., 5.12004772e-05, 7.64069482e-05, 6.71296293e-05], [7.56163136e-05, 7.60601688e-05, 5.15421052e-05, ..., 5.12004772e-05, 7.64069482e-05, 6.71296293e-05], [7.56163136e-05, 7.60601688e-05, 5.15421052e-05, ..., 5.12004772e-05, 7.64069482e-05, 6.71296293e-05], ..., [0.00000000e+00, 0.00000000e+00, 7.92784340e-06, ..., 2.89351846e-07, 9.61138994e-07, 8.68055565e-07], [0.00000000e+00, 0.00000000e+00, 7.92784340e-06, ..., 2.89351846e-07, 9.61138994e-07, 8.68055565e-07], [2.52938185e-06, 2.56903422e-06, 1.60732616e-05, ..., 1.76133108e-05, 1.61329936e-05, 1.41782411e-05]]) - airtemp(time, hru)float64279.2 279.1 287.9 ... 277.8 278.0
- long_name :
- air temperature at the measurement height (instant)
- units :
- K
array([[279.16464233, 279.10180664, 287.88330078, ..., 279.55426025, 277.30725098, 277.47616577], [277.83862305, 277.77490234, 286.64276123, ..., 278.72442627, 276.37030029, 276.52346802], [276.68637085, 276.62182617, 285.56466675, ..., 278.00335693, 275.55612183, 275.69558716], ..., [282.53366089, 282.48223877, 289.32037354, ..., 281.45050049, 279.69995117, 279.85458374], [280.41363525, 280.36248779, 287.4588623 , ..., 280.25997925, 278.4954834 , 278.64541626], [280.35980225, 280.31335449, 288.38198853, ..., 279.47991943, 277.83065796, 277.98855591]]) - windspd_mean(time, hru)float640.8894 0.8894 1.166 ... 1.265 1.266
- long_name :
- wind speed at the measurement height (mean)
- units :
- m s-1
array([[0.88942987, 0.8894136 , 1.16556144, ..., 1.46989083, 1.52078903, 1.52110004], [0.88942987, 0.8894136 , 1.16556144, ..., 1.46989083, 1.52078903, 1.52110004], [0.88942987, 0.8894136 , 1.16556144, ..., 1.46989083, 1.52078903, 1.52110004], ..., [2.54002619, 2.53933144, 2.87046552, ..., 2.1676178 , 2.15637445, 2.1572001 ], [2.54002619, 2.53933144, 2.87046552, ..., 2.1676178 , 2.15637445, 2.1572001 ], [1.60224426, 1.60180855, 1.77113569, ..., 1.29701996, 1.2652241 , 1.26619995]]) - SWRadAtm(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- downward shortwave radiation at the upper boundary (instant)
- units :
- W m-2
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - LWRadAtm(time, hru)float64287.4 287.1 333.5 ... 287.8 288.3
- long_name :
- downward longwave radiation at the upper boundary (instant)
- units :
- W m-2
array([[287.40258789, 287.07562256, 333.48782349, ..., 296.21936035, 282.74954224, 283.06121826], [282.04776001, 281.72177124, 327.86801147, ..., 292.76242065, 278.99124146, 279.23876953], [277.45541382, 277.13037109, 323.04211426, ..., 289.78302002, 275.75579834, 275.94857788], ..., [267.30368042, 267.06115723, 329.26171875, ..., 296.42745972, 288.24688721, 288.90286255], [259.50274658, 259.26660156, 321.00296021, ..., 291.51055908, 283.37393188, 284.00302124], [281.47229004, 281.27328491, 319.14331055, ..., 297.82312012, 287.81790161, 288.33462524]]) - scalarCanopyIce(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- mass of ice on the vegetation canopy (instant)
- units :
- kg m-2
array([[0. , 0. , 0. , ..., 0. , 0. , 0. ], [0. , 0. , 0. , ..., 0. , 0. , 0. ], [0. , 0. , 0. , ..., 0. , 0.02319168, 0.00730556], ..., [0. , 0. , 0. , ..., 0. , 0. , 0. ], [0. , 0. , 0. , ..., 0. , 0. , 0. ], [0. , 0. , 0. , ..., 0. , 0. , 0. ]]) - scalarCanopyLiq(time, hru)float640.2849 0.2866 ... 0.08693 0.07626
- long_name :
- mass of liquid water on the vegetation canopy (instant)
- units :
- kg m-2
array([[0.2848862 , 0.28661225, 0.35087317, ..., 0.25528067, 0.3613199 , 0.31721344], [0.55707802, 0.56040242, 0.54042229, ..., 0.44082329, 0.63726835, 0.55965798], [0.82944329, 0.83436647, 0.73040318, ..., 0.62767783, 0.89150277, 0.79635616], ..., [0.00523263, 0.00523645, 0.07405508, ..., 0.01060338, 0.03065529, 0.0269997 ], [0.00522588, 0.00522969, 0.09879395, ..., 0.01104933, 0.03200753, 0.02820905], [0.01282898, 0.01295744, 0.15836067, ..., 0.07099386, 0.08693351, 0.07625861]]) - scalarCanopyWat_mean(time, hru)float640.2849 0.2866 ... 0.08693 0.07626
- long_name :
- mass of total water on the vegetation canopy (mean)
- units :
- kg m-2
array([[0.2848862 , 0.28661225, 0.35087317, ..., 0.25528067, 0.3613199 , 0.31721344], [0.55707802, 0.56040242, 0.54042229, ..., 0.44082329, 0.63726835, 0.55965798], [0.82944329, 0.83436647, 0.73040318, ..., 0.62767783, 0.91469445, 0.80366172], ..., [0.00523263, 0.00523645, 0.07405508, ..., 0.01060338, 0.03065529, 0.0269997 ], [0.00522588, 0.00522969, 0.09879395, ..., 0.01104933, 0.03200753, 0.02820905], [0.01282898, 0.01295744, 0.15836067, ..., 0.07099386, 0.08693351, 0.07625861]]) - scalarCanairTemp(time, hru)float64275.7 275.6 282.1 ... 275.6 275.8
- long_name :
- temperature of the canopy air space (instant)
- units :
- K
array([[275.67493913, 275.61897099, 282.13812679, ..., 276.5496316 , 274.51310888, 274.63401125], [274.6583324 , 274.59992024, 281.88236478, ..., 275.86111914, 273.72431877, 273.82292771], [273.79851508, 273.73867956, 281.44635536, ..., 275.33920245, 273.25997274, 273.26301317], ..., [281.52671199, 281.47458662, 285.01133945, ..., 280.74910573, 278.95596146, 279.11499477], [279.53404011, 279.48192071, 283.28165643, ..., 279.5529211 , 277.74530593, 277.901004 ], [276.95616383, 276.90417864, 281.9011963 , ..., 277.4979156 , 275.61958526, 275.7662665 ]]) - scalarCanopyTemp(time, hru)float64275.6 275.5 282.1 ... 275.5 275.6
- long_name :
- temperature of the vegetation canopy (instant)
- units :
- K
array([[275.5898463 , 275.53362052, 282.10450556, ..., 276.44422027, 274.38967576, 274.51008951], [274.58872865, 274.53015735, 281.84347191, ..., 275.76600997, 273.61315019, 273.71158479], [273.7375521 , 273.67761803, 281.40141704, ..., 275.24874308, 273.15677422, 273.15808441], ..., [280.99633119, 280.94439876, 284.94327306, ..., 280.39597057, 278.60141797, 278.7604709 ], [279.03835098, 278.98636991, 283.20519399, ..., 279.21507167, 277.40745324, 277.56311727], [276.76309563, 276.71128983, 281.87593833, ..., 277.34612592, 275.47096086, 275.61721434]]) - scalarSnowAlbedo(time, hru)float64-9.999e+03 ... -9.999e+03
- long_name :
- snow albedo for the entire spectral band (instant)
- units :
- -
array([[-9999., -9999., -9999., ..., -9999., -9999., -9999.], [-9999., -9999., -9999., ..., -9999., -9999., -9999.], [-9999., -9999., -9999., ..., -9999., -9999., -9999.], ..., [-9999., -9999., -9999., ..., -9999., -9999., -9999.], [-9999., -9999., -9999., ..., -9999., -9999., -9999.], [-9999., -9999., -9999., ..., -9999., -9999., -9999.]]) - scalarSnowDepth_mean(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- total snow depth (mean)
- units :
- m
array([[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [5.95065803e-10, 6.71683864e-10, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]) - scalarSWE(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- snow water equivalent (instant)
- units :
- kg m-2
array([[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [8.92598704e-08, 1.00752580e-07, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]) - mLayerTemp_mean(time, midToto, hru)float64281.0 281.0 ... -9.999e+03
- long_name :
- temperature of each layer (mean)
- units :
- K
array([[[ 281.01348304, 280.96274488, 286.23043799, ..., 280.43873073, 278.69752846, 278.84283714], [ 281.73704322, 281.68621174, 287.23176891, ..., 280.96916059, 279.25721178, 279.40621677], [ 281.87887428, 281.82764699, 287.87448249, ..., 281.11595109, 279.42198287, 279.57182636], ..., [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ]], [[ 280.54024602, 280.48915431, 285.81529782, ..., 280.09974108, 278.33034657, 278.4705361 ], [ 281.36612715, 281.31522321, 286.8483686 , ..., 280.7094432 , 278.98149345, 279.12766476], [ 281.78925887, 281.73810036, 287.74284 , ..., 281.05507782, 279.35631722, 279.50560905], ... [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ]], [[ 281.50267905, 281.45215995, 286.81199433, ..., 280.80265241, 279.08511166, 279.23546735], [ 282.10756768, 282.0563797 , 287.8339394 , ..., 281.21854807, 279.51019407, 279.66207391], [ 281.92149854, 281.86973562, 288.18195298, ..., 281.13592528, 279.43489511, 279.58600375], ..., [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ], [-9999. , -9999. , -9999. , ..., -9999. , -9999. , -9999. ]]]) - scalarSurfaceTemp(time, hru)float64281.0 281.0 286.2 ... 279.1 279.2
- long_name :
- surface temperature (just a copy of the upper-layer temperature) (instant)
- units :
- K
array([[281.01348304, 280.96274488, 286.23043799, ..., 280.43873073, 278.69752846, 278.84283714], [280.54024602, 280.48915431, 285.81529782, ..., 280.09974108, 278.33034657, 278.4705361 ], [280.09935275, 280.04798328, 285.40362561, ..., 279.79539676, 278.01405943, 278.1405834 ], ..., [282.78789386, 282.73631115, 288.34826687, ..., 281.63185555, 279.92142551, 280.07575016], [282.09769348, 282.04672115, 287.39572212, ..., 281.23163826, 279.52051871, 279.67307917], [281.50267905, 281.45215995, 286.81199433, ..., 280.80265241, 279.08511166, 279.23546735]]) - mLayerDepth_mean(time, midToto, hru)float640.025 0.025 ... -9.999e+03
- long_name :
- depth of each layer (mean)
- units :
- m
array([[[ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 7.500e-02, 7.500e-02, 7.500e-02, ..., 7.500e-02, 7.500e-02, 7.500e-02], [ 1.500e-01, 1.500e-01, 1.500e-01, ..., 1.500e-01, 1.500e-01, 1.500e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 7.500e-02, 7.500e-02, 7.500e-02, ..., 7.500e-02, 7.500e-02, 7.500e-02], [ 1.500e-01, 1.500e-01, 1.500e-01, ..., 1.500e-01, 1.500e-01, 1.500e-01], ... [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 7.500e-02, 7.500e-02, 7.500e-02, ..., 7.500e-02, 7.500e-02, 7.500e-02], [ 1.500e-01, 1.500e-01, 1.500e-01, ..., 1.500e-01, 1.500e-01, 1.500e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]]]) - mLayerHeight_mean(time, midToto, hru)float640.0125 0.0125 ... -9.999e+03
- long_name :
- height of the layer mid-point (top of soil = 0) (mean)
- units :
- m
array([[[ 1.250e-02, 1.250e-02, 1.250e-02, ..., 1.250e-02, 1.250e-02, 1.250e-02], [ 6.250e-02, 6.250e-02, 6.250e-02, ..., 6.250e-02, 6.250e-02, 6.250e-02], [ 1.750e-01, 1.750e-01, 1.750e-01, ..., 1.750e-01, 1.750e-01, 1.750e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[ 1.250e-02, 1.250e-02, 1.250e-02, ..., 1.250e-02, 1.250e-02, 1.250e-02], [ 6.250e-02, 6.250e-02, 6.250e-02, ..., 6.250e-02, 6.250e-02, 6.250e-02], [ 1.750e-01, 1.750e-01, 1.750e-01, ..., 1.750e-01, 1.750e-01, 1.750e-01], ... [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[ 1.250e-02, 1.250e-02, 1.250e-02, ..., 1.250e-02, 1.250e-02, 1.250e-02], [ 6.250e-02, 6.250e-02, 6.250e-02, ..., 6.250e-02, 6.250e-02, 6.250e-02], [ 1.750e-01, 1.750e-01, 1.750e-01, ..., 1.750e-01, 1.750e-01, 1.750e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]]]) - iLayerHeight_mean(time, ifcToto, hru)float64-0.0 -0.0 ... -9.999e+03 -9.999e+03
- long_name :
- height of the layer interface (top of soil = 0) (mean)
- units :
- m
array([[[-0.000e+00, -0.000e+00, -0.000e+00, ..., -0.000e+00, -0.000e+00, -0.000e+00], [ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 1.000e-01, 1.000e-01, 1.000e-01, ..., 1.000e-01, 1.000e-01, 1.000e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[-0.000e+00, -0.000e+00, -0.000e+00, ..., -0.000e+00, -0.000e+00, -0.000e+00], [ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 1.000e-01, 1.000e-01, 1.000e-01, ..., 1.000e-01, 1.000e-01, 1.000e-01], ... [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]], [[-0.000e+00, -0.000e+00, -0.000e+00, ..., -0.000e+00, -0.000e+00, -0.000e+00], [ 2.500e-02, 2.500e-02, 2.500e-02, ..., 2.500e-02, 2.500e-02, 2.500e-02], [ 1.000e-01, 1.000e-01, 1.000e-01, ..., 1.000e-01, 1.000e-01, 1.000e-01], ..., [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03], [-9.999e+03, -9.999e+03, -9.999e+03, ..., -9.999e+03, -9.999e+03, -9.999e+03]]]) - scalarTotalSoilLiq(time, hru)float641.169e+03 1.172e+03 ... 1.273e+03
- long_name :
- total mass of liquid water in the soil (instant)
- units :
- kg m-2
array([[1169.4861494 , 1171.95923543, 958.16016633, ..., 1273.18576626, 1275.53986186, 1272.82216379], [1169.48593486, 1171.95901743, 958.15606966, ..., 1273.16738024, 1275.51940637, 1272.80433547], [1169.48570129, 1171.95878033, 958.15155395, ..., 1273.14902732, 1275.4989666 , 1272.78651745], ..., [1160.41594809, 1163.19740491, 934.31440308, ..., 1273.25450403, 1275.61803344, 1272.8950666 ], [1160.40710502, 1163.18858504, 934.30586475, ..., 1273.23245505, 1275.5942375 , 1272.87383523], [1160.40161177, 1163.18311216, 934.30247678, ..., 1273.21199869, 1275.57230158, 1272.85442138]]) - scalarTotalSoilIce(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- total mass of ice in the soil (instant)
- units :
- kg m-2
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarCanairNetNrgFlux(time, hru)float64-5.337 -5.354 ... -8.824 -8.861
- long_name :
- net energy flux for the canopy air space (instant)
- units :
- W m-2
array([[ -5.33665068, -5.35352425, 0.05145734, ..., -3.95640942, -4.62416228, -4.73023102], [ -4.22000441, -4.2301497 , -0.04154422, ..., -2.85806254, -3.27432198, -3.36686352], [ -3.56916084, -3.57506927, -0.07082237, ..., -2.1665121 , -1.92753229, -2.32424376], ..., [-10.83225207, -10.83626063, -0.48038826, ..., -6.76362156, -6.9601605 , -6.95940903], [ -8.27172309, -8.27169831, -0.28095782, ..., -4.96582636, -5.02593892, -5.03980611], [-10.70094166, -10.70038454, -0.22423245, ..., -8.53046911, -8.82401264, -8.86144212]]) - scalarCanopyNetNrgFlux(time, hru)float64-7.165 -7.193 ... -11.83 -11.87
- long_name :
- net energy flux for the vegetation canopy (instant)
- units :
- W m-2
array([[ -7.16526191, -7.19282902, 1.92615247, ..., -5.57814736, -6.71831698, -6.86256314], [ -6.40746141, -6.42448501, -1.6907005 , ..., -4.31743565, -5.03893454, -5.1406557 ], [ -5.71686661, -5.72931113, -2.96047905, ..., -3.40434639, -5.2589829 , -4.39825206], ..., [-16.54630604, -16.55311868, -18.18739624, ..., -10.65658065, -10.96970299, -10.95864699], [-11.895751 , -11.89605518, -10.6986609 , ..., -7.18194346, -7.2892121 , -7.30481812], [-13.48716293, -13.46511197, -8.22035976, ..., -11.36744576, -11.82541851, -11.87430079]]) - scalarGroundNetNrgFlux(time, hru)float64-27.66 -27.68 ... -18.96 -19.02
- long_name :
- net energy flux for the ground surface (instant)
- units :
- W m-2
array([[-27.6617224 , -27.67563288, -31.05321773, ..., -20.93508828, -22.27298511, -22.42966287], [-30.0221631 , -30.04327782, -31.50906674, ..., -22.51597493, -24.14809286, -24.38020319], [-31.81858976, -31.84314524, -32.78135098, ..., -23.51288278, -24.842537 , -25.42867012], ..., [-14.68521427, -14.67404115, -31.16969028, ..., -9.17460693, -9.40513528, -9.41526243], [-22.02694495, -22.01279323, -36.67175578, ..., -13.34320421, -13.53238615, -13.56492797], [-25.86526886, -25.85248614, -33.17731067, ..., -18.58323122, -18.95967152, -19.02203735]]) - scalarLWNetUbound(time, hru)float64-40.71 -40.77 ... -39.37 -39.55
- long_name :
- net longwave radiation at the upper atmospheric boundary (instant)
- units :
- W m-2
array([[-40.7119976 , -40.77255112, -29.56254598, ..., -35.70264643, -39.47904496, -39.73771877], [-41.43011564, -41.48187658, -33.68592205, ..., -35.98100097, -39.6841971 , -39.90304466], [-42.11204292, -42.1592099 , -36.27644994, ..., -36.54286069, -40.82637954, -40.6631726 ], ..., [-86.56497836, -86.54610288, -46.09317066, ..., -54.32188429, -53.62624578, -53.75060794], [-84.84958573, -84.82951129, -45.64387655, ..., -53.51608015, -52.82481146, -52.95017138], [-52.10863573, -52.05836084, -41.01446837, ..., -38.33150601, -39.37095617, -39.55003625]]) - scalarSenHeatTotal(time, hru)float640.4441 0.4447 ... 3.265 3.267
- long_name :
- sensible heat from the canopy air space to the atmosphere (instant)
- units :
- W m-2
array([[ 0.44411986, 0.44468515, 0.11072185, ..., 5.15839293, 6.21129545, 6.15150459], [ 0.47860871, 0.47907692, 0.12996642, ..., 5.31007931, 6.40581411, 6.33080321], [ 0.51754829, 0.51802478, 0.14645162, ..., 5.55707042, 6.9818517 , 6.74439461], ..., [50.72431645, 50.68940054, 6.55259368, ..., 31.12284583, 30.96579041, 30.9723003 ], [48.76206028, 48.73818752, 6.56791198, ..., 31.08201682, 30.91102234, 30.90741575], [ 6.9032337 , 6.88520143, 0.66789982, ..., 3.96197726, 3.26461065, 3.2671361 ]]) - scalarLatHeatTotal(time, hru)float64-0.2061 -0.2063 ... -3.415 -3.392
- long_name :
- latent heat from the canopy air space to the atmosphere (instant)
- units :
- W m-2
array([[-2.06107360e-01, -2.06276121e-01, -3.38701350e-02, ..., -2.42349205e-01, -7.60195704e-01, -7.97535232e-01], [-1.12236512e-01, -1.11969883e-01, -3.69461340e-02, ..., 6.04657124e-01, 3.11418266e-01, 2.37182844e-01], [-4.98399297e-03, -4.46892466e-03, -2.81129545e-02, ..., 1.49331460e+00, 1.30049622e+00, 1.28653661e+00], ..., [-6.22311047e+00, -6.20671813e+00, -1.02372882e+01, ..., -3.39333648e+00, -4.66706950e+00, -4.54806218e+00], [-6.10689359e+00, -6.08922296e+00, -8.54602503e+00, ..., -3.05520452e+00, -3.92863922e+00, -3.86199258e+00], [-4.81910825e+00, -4.81596960e+00, -1.14393032e+00, ..., -3.99021763e+00, -3.41458641e+00, -3.39159389e+00]]) - scalarLatHeatCanopyEvap(time, hru)float64-0.1114 -0.1116 ... -2.19 -2.079
- long_name :
- evaporation latent heat from the canopy to the canopy air space (instant)
- units :
- W m-2
array([[-0.11138575, -0.11155042, 2.53971121, ..., -0.01823886, -0.44549586, -0.47221855], [-0.01869067, -0.0183685 , 2.75904364, ..., 0.78904184, 0.58381453, 0.51035764], [ 0.09697385, 0.09759279, 3.06324936, ..., 1.6737568 , 1.58429569, 1.56114712], ..., [-0.00619367, -0.00620172, -4.38979927, ..., -0.46854264, -1.91010885, -1.72613427], [-0.00469088, -0.00469568, -2.64089253, ..., -0.41386125, -1.46437811, -1.33084503], [-1.04388356, -1.05644678, 1.13896614, ..., -2.40609233, -2.19031967, -2.07868264]]) - scalarLatHeatCanopyTrans(time, hru)float64-0.01746 -0.01739 ... -1.063
- long_name :
- transpiration latent heat from the canopy to the canopy air space (instant)
- units :
- W m-2
array([[-1.74575918e-02, -1.73872409e-02, 2.74845684e-02, ..., -2.42216841e-03, -4.18324180e-02, -5.07091396e-02], [-1.44201745e-03, -1.40919656e-03, 1.81410577e-02, ..., 5.91467664e-02, 2.99288471e-02, 3.00441578e-02], [ 4.83327931e-03, 4.83584456e-03, 1.38920331e-02, ..., 8.58521767e-02, 5.60135036e-02, 6.24776902e-02], ..., [-3.93704858e+00, -3.92792251e+00, -2.91023598e-01, ..., -2.00490525e+00, -1.88679749e+00, -1.93359682e+00], [-2.98695972e+00, -2.97925440e+00, -1.29880304e-01, ..., -1.47757427e+00, -1.38022181e+00, -1.42155294e+00], [-3.01589274e+00, -3.00427284e+00, 4.41336281e-02, ..., -1.26607792e+00, -9.82665496e-01, -1.06253808e+00]]) - scalarLatHeatGround(time, hru)float64-0.07726 -0.07734 ... -0.2504
- long_name :
- latent heat from the ground (below canopy or non-vegetated) (instant)
- units :
- W m-2
array([[-0.07726401, -0.07733846, -2.60106591, ..., -0.22168818, -0.27286743, -0.27460755], [-0.09210382, -0.09219219, -2.81413083, ..., -0.24353148, -0.30232511, -0.30321896], [-0.10679112, -0.10689756, -3.10525435, ..., -0.26629438, -0.33981297, -0.3370882 ], ..., [-2.27986822, -2.27259389, -5.55646537, ..., -0.91988859, -0.87016316, -0.88833109], [-3.11524299, -3.10527288, -5.7752522 , ..., -1.163769 , -1.08403931, -1.1095946 ], [-0.75933195, -0.75524998, -2.32703009, ..., -0.31804738, -0.24160124, -0.25037317]]) - scalarCanopySublimation(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- canopy sublimation/frost (instant)
- units :
- kg m-2 s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarSnowSublimation(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- snow sublimation/frost (below canopy or non-vegetated) (instant)
- units :
- kg m-2 s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarCanopyTranspiration(time, hru)float64-6.98e-09 -6.952e-09 ... -4.248e-07
- long_name :
- canopy transpiration (instant)
- units :
- kg m-2 s-1
array([[-6.98024461e-09, -6.95211551e-09, 0.00000000e+00, ..., -9.68479974e-10, -1.67262767e-08, -2.02755456e-08], [-5.76576348e-10, -5.63453245e-10, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [-1.57418976e-06, -1.57054079e-06, -1.16362894e-07, ..., -8.01641444e-07, -7.54417230e-07, -7.73129476e-07], [-1.19430617e-06, -1.19122527e-06, -5.19313490e-08, ..., -5.90793389e-07, -5.51867977e-07, -5.68393818e-07], [-1.20587475e-06, -1.20122864e-06, 0.00000000e+00, ..., -5.06228676e-07, -3.92909035e-07, -4.24845293e-07]]) - scalarCanopyEvaporation(time, hru)float64-4.454e-08 -4.46e-08 ... -8.311e-07
- long_name :
- canopy evaporation/condensation (instant)
- units :
- kg m-2 s-1
array([[-4.45364868e-08, -4.46023283e-08, 1.02646772e-06, ..., -7.29262585e-09, -1.78127093e-07, -1.88811894e-07], [-7.47327902e-09, -7.34446246e-09, 1.11042971e-06, ..., 3.39139787e-07, 2.45399190e-07, 2.16074291e-07], [ 4.07065672e-08, 4.09550726e-08, 1.23036441e-06, ..., 7.03562167e-07, 6.55861332e-07, 6.49190248e-07], ..., [-2.47647636e-09, -2.47969791e-09, -1.75521762e-06, ..., -1.87342119e-07, -7.63738046e-07, -6.90177636e-07], [-1.87560111e-09, -1.87752208e-09, -1.05593464e-06, ..., -1.65478309e-07, -5.85517036e-07, -5.32125163e-07], [-4.17386470e-07, -4.22409750e-07, 4.73050685e-07, ..., -9.62052110e-07, -8.75777557e-07, -8.31140599e-07]]) - scalarGroundEvaporation(time, hru)float64-3.089e-08 ... -1.001e-07
- long_name :
- ground evaporation/condensation (below canopy or non-vegetated) (instant)
- units :
- kg m-2 s-1
array([[-3.08932487e-08, -3.09230134e-08, -1.04001036e-06, ..., -8.86398160e-08, -1.09103329e-07, -1.09799099e-07], [-3.68267990e-08, -3.68621294e-08, -1.12520225e-06, ..., -9.73736442e-08, -1.20881691e-07, -1.21239088e-07], [-4.26993673e-08, -4.27419277e-08, -1.24160510e-06, ..., -1.06475160e-07, -1.35870839e-07, -1.34781368e-07], ..., [-9.11582656e-07, -9.08674088e-07, -2.22169747e-06, ..., -3.67808311e-07, -3.47926093e-07, -3.55190359e-07], [-1.24559896e-06, -1.24161250e-06, -2.30917721e-06, ..., -4.65321472e-07, -4.33442346e-07, -4.43660378e-07], [-3.03611334e-07, -3.01979199e-07, -9.30439859e-07, ..., -1.27168086e-07, -9.66018551e-08, -1.00109225e-07]]) - scalarThroughfallSnow(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- snow that reaches the ground without ever touching the canopy (instant)
- units :
- kg m-2 s-1
array([[0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [2.47944085e-11, 2.79868277e-11, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]) - scalarThroughfallRain(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- rain that reaches the ground without ever touching the canopy (instant)
- units :
- kg m-2 s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarCanopySnowUnloading_mean(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- unloading of snow from the vegetation canopy (mean)
- units :
- kg m-2 s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarRainPlusMelt(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- rain plus melt, used as input to soil before surface runoff (instant)
- units :
- m s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarInfiltration(time, hru)float642.479e-14 2.799e-14 0.0 ... 0.0 0.0
- long_name :
- infiltration of water into the soil profile (instant)
- units :
- m s-1
array([[2.47944085e-14, 2.79868277e-14, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]) - scalarExfiltration(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- exfiltration of water from the top of the soil profile (instant)
- units :
- m s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarSurfaceRunoff(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- surface runoff (instant)
- units :
- m s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarSoilBaseflow(time, hru)float640.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0
- long_name :
- total baseflow from the soil profile (instant)
- units :
- m s-1
array([[0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.]]) - scalarAquiferBaseflow(time, hru)float642.228e-11 2.322e-11 ... 4.876e-09
- long_name :
- baseflow from the aquifer (instant)
- units :
- m s-1
array([[2.22791761e-11, 2.32214883e-11, 1.25935985e-11, ..., 5.03750135e-09, 5.58997037e-09, 4.85598286e-09], [2.22685802e-11, 2.32103178e-11, 1.25902365e-11, ..., 5.01888132e-09, 5.57026701e-09, 4.83930571e-09], [2.22579922e-11, 2.31991558e-11, 1.25868743e-11, ..., 5.00048979e-09, 5.55081344e-09, 4.82282242e-09], ..., [1.64822147e-11, 1.71062142e-11, 1.03332838e-11, ..., 5.09654926e-09, 5.65375134e-09, 4.91053191e-09], [1.64758234e-11, 1.70994585e-11, 1.03299416e-11, ..., 5.07723255e-09, 5.63328546e-09, 4.89326018e-09], [1.64694358e-11, 1.70927066e-11, 1.03265985e-11, ..., 5.05814454e-09, 5.61306857e-09, 4.87618136e-09]]) - scalarTotalRunoff(time, hru)float642.228e-11 2.322e-11 ... 4.876e-09
- long_name :
- total runoff (instant)
- units :
- m s-1
array([[2.22791761e-11, 2.32214883e-11, 1.25935985e-11, ..., 5.03750135e-09, 5.58997037e-09, 4.85598286e-09], [2.22685802e-11, 2.32103178e-11, 1.25902365e-11, ..., 5.01888132e-09, 5.57026701e-09, 4.83930571e-09], [2.22579922e-11, 2.31991558e-11, 1.25868743e-11, ..., 5.00048979e-09, 5.55081344e-09, 4.82282242e-09], ..., [1.64822147e-11, 1.71062142e-11, 1.03332838e-11, ..., 5.09654926e-09, 5.65375134e-09, 4.91053191e-09], [1.64758234e-11, 1.70994585e-11, 1.03299416e-11, ..., 5.07723255e-09, 5.63328546e-09, 4.89326018e-09], [1.64694358e-11, 1.70927066e-11, 1.03265985e-11, ..., 5.05814454e-09, 5.61306857e-09, 4.87618136e-09]]) - scalarNetRadiation(time, hru)float64-40.71 -40.77 ... -39.37 -39.55
- long_name :
- net radiation (instant)
- units :
- W m-2
array([[-40.7119976 , -40.77255112, -29.56254598, ..., -35.70264643, -39.47904496, -39.73771877], [-41.43011564, -41.48187658, -33.68592205, ..., -35.98100097, -39.6841971 , -39.90304466], [-42.11204292, -42.1592099 , -36.27644994, ..., -36.54286069, -40.82637954, -40.6631726 ], ..., [-86.56497836, -86.54610288, -46.09317066, ..., -54.32188429, -53.62624578, -53.75060794], [-84.84958573, -84.82951129, -45.64387655, ..., -53.51608015, -52.82481146, -52.95017138], [-52.10863573, -52.05836084, -41.01446837, ..., -38.33150601, -39.37095617, -39.55003625]]) - hruId(hru)int6417006965 17006967 ... 17009664
- long_name :
- ID defining the hydrologic response unit
- units :
- -
array([17006965, 17006967, 17006969, 17006970, 17006971, 17006972, 17006973, 17006974, 17006976, 17006978, 17006979, 17006980, 17006982, 17006984, 17006985, 17006986, 17006987, 17006988, 17006989, 17006990, 17006991, 17006992, 17006993, 17006994, 17006995, 17006996, 17006997, 17006998, 17006999, 17007000, 17007001, 17007002, 17007003, 17007004, 17007005, 17007007, 17007008, 17007013, 17007014, 17007016, 17007017, 17007018, 17007020, 17007021, 17007022, 17007023, 17007024, 17007025, 17007026, 17007030, 17007031, 17007032, 17007033, 17007034, 17007035, 17007036, 17007037, 17007038, 17007039, 17007040, 17007041, 17007042, 17007043, 17007044, 17007045, 17007046, 17007047, 17007048, 17007049, 17007050, 17007052, 17007053, 17007055, 17007057, 17007058, 17007059, 17007060, 17007061, 17007062, 17007063, 17007064, 17007065, 17007067, 17007068, 17007069, 17007070, 17007072, 17007073, 17007074, 17007075, 17007076, 17007079, 17007080, 17007081, 17007082, 17007083, 17007085, 17007088, 17007090, 17007092, 17007097, 17007098, 17007105, 17007106, 17007107, 17007108, 17007111, 17007112, 17007118, 17007119, 17007125, 17007126, 17007127, 17007129, 17007131, 17007132, 17007134, 17007135, 17007137, 17007139, ... 17007255, 17007257, 17007258, 17007261, 17007265, 17007270, 17007272, 17007280, 17007282, 17007287, 17007291, 17007299, 17007308, 17007309, 17007313, 17007318, 17007321, 17007322, 17007323, 17007327, 17007328, 17007330, 17007337, 17007341, 17007344, 17007346, 17007350, 17007366, 17007367, 17007376, 17007389, 17007390, 17007391, 17007394, 17007397, 17007398, 17007401, 17007402, 17007404, 17007408, 17007415, 17007425, 17007427, 17007433, 17007440, 17007466, 17007468, 17007474, 17007491, 17007492, 17007494, 17007518, 17007534, 17007557, 17007576, 17007611, 17007640, 17007647, 17007670, 17007677, 17007679, 17007727, 17007729, 17007755, 17007759, 17007760, 17007763, 17007768, 17009407, 17009416, 17009418, 17009420, 17009421, 17009423, 17009424, 17009425, 17009426, 17009427, 17009433, 17009434, 17009435, 17009436, 17009437, 17009438, 17009501, 17009502, 17009505, 17009506, 17009508, 17009509, 17009510, 17009511, 17009512, 17009513, 17009518, 17009519, 17009524, 17009531, 17009532, 17009537, 17009538, 17009541, 17009542, 17009547, 17009550, 17009567, 17009568, 17009569, 17009570, 17009581, 17009582, 17009595, 17009596, 17009603, 17009604, 17009662, 17009664]) - averageInstantRunoff(time, gru)float644.448e-11 4.636e-11 ... 9.744e-09
- long_name :
- instantaneous runoff (instant)
- units :
- m s-1
array([[4.44811433e-11, 4.63632503e-11, 2.51546387e-11, ..., 1.00658819e-08, 1.11707745e-08, 9.70365019e-09], [4.44599878e-11, 4.63409467e-11, 2.51479061e-11, ..., 1.00287367e-08, 1.11314675e-08, 9.67037805e-09], [4.44388514e-11, 4.63186631e-11, 2.51411757e-11, ..., 9.99204790e-09, 1.10926596e-08, 9.63749324e-09], ..., [3.29102927e-11, 3.41562588e-11, 2.06308432e-11, ..., 1.01836988e-08, 1.12980446e-08, 9.81250712e-09], [3.28975285e-11, 3.41427658e-11, 2.06241411e-11, ..., 1.01451557e-08, 1.12572067e-08, 9.77804088e-09], [3.28847740e-11, 3.41292831e-11, 2.06174413e-11, ..., 1.01070724e-08, 1.12168700e-08, 9.74396312e-09]]) - averageRoutedRunoff(time, gru)float644.459e-11 4.648e-11 ... 9.92e-09
- long_name :
- routed runoff (instant)
- units :
- m s-1
array([[4.45884281e-11, 4.64763557e-11, 2.51886770e-11, ..., 1.02618630e-08, 1.13781799e-08, 9.87866192e-09], [4.45671958e-11, 4.64539716e-11, 2.51819454e-11, ..., 1.02228841e-08, 1.13369436e-08, 9.84387415e-09], [4.45459776e-11, 4.64316023e-11, 2.51752129e-11, ..., 1.01842288e-08, 1.12960410e-08, 9.80935063e-09], ..., [3.29749715e-11, 3.42246281e-11, 2.06646899e-11, ..., 1.03839193e-08, 1.15097191e-08, 9.99097777e-09], [3.29621732e-11, 3.42110995e-11, 2.06579984e-11, ..., 1.03442629e-08, 1.14678334e-08, 9.95565040e-09], [3.29493809e-11, 3.41975774e-11, 2.06513039e-11, ..., 1.03047681e-08, 1.14260844e-08, 9.92044113e-09]]) - gruId(gru)int64906922 906924 ... 909581 909583
- long_name :
- ID defining the grouped (basin) response unit
- units :
- -
array([906922, 906924, 906926, 906927, 906928, 906929, 906930, 906931, 906933, 906935, 906936, 906937, 906939, 906941, 906942, 906943, 906944, 906945, 906946, 906947, 906948, 906949, 906950, 906951, 906952, 906953, 906954, 906955, 906956, 906957, 906958, 906959, 906960, 906961, 906962, 906964, 906965, 906970, 906971, 906973, 906974, 906975, 906977, 906978, 906979, 906980, 906981, 906982, 906983, 906987, 906988, 906989, 906990, 906991, 906992, 906993, 906994, 906995, 906996, 906997, 906998, 906999, 907000, 907001, 907002, 907003, 907004, 907005, 907006, 907007, 907009, 907010, 907012, 907014, 907015, 907016, 907017, 907018, 907019, 907020, 907021, 907022, 907024, 907025, 907026, 907027, 907029, 907030, 907031, 907032, 907033, 907036, 907037, 907038, 907039, 907040, 907042, 907045, 907047, 907049, 907054, 907055, 907062, 907063, 907064, 907065, 907068, 907069, 907075, 907076, 907082, 907083, 907084, 907086, 907088, 907089, 907091, 907092, 907094, 907096, 907098, 907099, 907100, 907101, 907104, 907107, 907110, 907113, 907114, 907115, 907118, 907121, 907123, 907125, 907126, 907127, 907128, 907130, 907131, 907132, 907134, 907135, 907136, 907139, 907142, 907143, 907147, 907149, 907156, 907163, 907166, 907168, 907170, 907184, 907185, 907186, 907188, 907190, 907193, 907194, 907198, 907200, 907201, 907202, 907206, 907207, 907209, 907211, 907212, 907214, 907215, 907218, 907222, 907227, 907229, 907237, 907239, 907244, 907248, 907256, 907265, 907266, 907270, 907275, 907278, 907279, 907280, 907284, 907285, 907287, 907294, 907298, 907301, 907303, 907307, 907323, 907324, 907333, 907346, 907347, 907348, 907351, 907354, 907355, 907358, 907359, 907361, 907365, 907372, 907382, 907384, 907390, 907397, 907423, 907425, 907431, 907448, 907449, 907451, 907475, 907491, 907514, 907533, 907568, 907597, 907604, 907627, 907634, 907636, 907684, 907686, 907712, 907716, 907717, 907720, 907725, 909326, 909335, 909337, 909339, 909340, 909342, 909343, 909344, 909345, 909346, 909352, 909353, 909354, 909355, 909356, 909357, 909420, 909421, 909424, 909425, 909427, 909428, 909429, 909430, 909431, 909432, 909437, 909438, 909443, 909450, 909451, 909456, 909457, 909460, 909461, 909466, 909469, 909486, 909487, 909488, 909489, 909500, 909501, 909514, 909515, 909522, 909523, 909581, 909583])
[6]:
shapefile = './data/yakima/shapefile/yakima.shp'
gdf = gpd.GeoDataFrame.from_file(shapefile)
fig = plt.figure(figsize=(12, 6))
gs = fig.add_gridspec(2, 2)
ax1 = fig.add_subplot(gs[0, 0], )
yakima_ds['pptrate'].plot.line(x='time', ax=ax1, add_legend=False, color='dimgrey', alpha=0.1)
ax1.set_xlabel('')
ax1.set_xticks([])
ax1.set_ylabel('Precipitation rate ($kg / m^2 s$)')
ax2 = fig.add_subplot(gs[1, 0], )
yakima_ds['scalarTotalSoilLiq'].plot.line(x='time', ax=ax2, add_legend=False, color='dimgrey', alpha=0.1)
ax2.set_ylabel('Total liquid water in\n the soil column ($kg/m^2$)')
ax2.set_xlabel('')
ax3 = fig.add_subplot(gs[:, 1], projection=ccrs.Mercator())
psp.spatial(yakima_ds['scalarTotalSoilLiq'].mean(dim='time'), gdf, ax=ax3)
[6]:
<GeoAxesSubplot:>
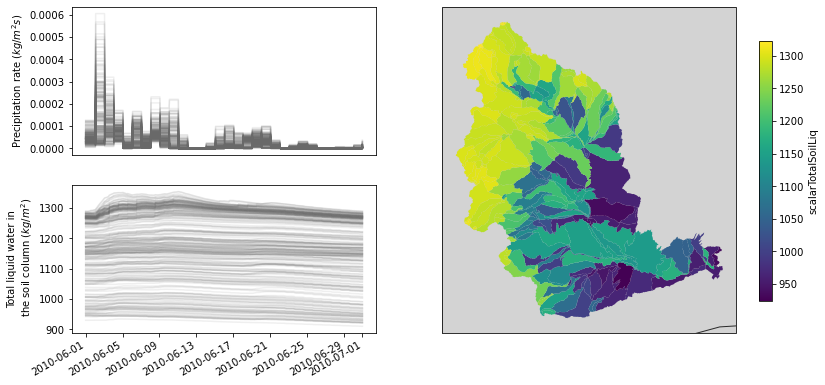
Further configuration, and more advanced parallelism¶
The Yakima River Basin given as an example here is a relatively small simulation of about 300 HRU for a month, but the parallelism approach built into the Distributed object can generally scale to many cores. Under the hood we rely on the `dask library <https://dask.org/>`__ to manage the scheduling of the parallel runs of both the Ensemble and Distributed objects. While we won’t actually run any simulations with these configurations, we show the code as a reference.
[7]:
from dask.distributed import Client
from dask.distributed import LocalCluster
from dask_jobqueue import SLURMCluster
For local runs (e.g. your laptop or a big workstation machine), you can use the LocalCluster. For use on HPC machines, you will probably need to submit your jobs to the scheduler. This can be done via `dask_jobqueue <https://jobqueue.dask.org/en/latest/>`__. Here we show how to use the SLURMCluster, but other schedulers are supported.
[ ]:
# Local example
N_WORKERS = 16 # A big machine might have 16 processors
local_cluster = LocalCluster(n_workers=N_WORKERS, threads_per_worker=1) # Each SUMMA simulation runs as a single-threaded process by default
local_example = Client(local_cluster) # This connects the compute cluster to the process running in this notebook
yakima_local = ps.Distributed(summa_exe, file_manager, client=local_example)
# If you have the resources, you can just call `yakima_local.run()` just as before
[ ]:
# SLURM example
N_WORKERS = 285 # On HPC maybe we want to run each GRU independently
slurm_cluster = SLURMCluster(cores=N_WORKERS, memory='4GB', # Set the number of cores and memory per worker
queue='default', project='Pxyzxyz') # Set your queue and project code
slurm_example = Client(slurm_cluster) # This connects the compute cluster to the process running in this notebook
yakima_slurm = ps.Distributed(summa_exe, file_manager, client=slurm_example)
# If you have the resources, you can just call `yakima_slurm.run()` just as before
[ ]:
Tutorial 4: Calibration of a point SUMMA simulation with Ostrich¶
This notebook outlines the initial work on interfacing Ostrich into the pysumma workflow. The basic workflow is similar to that of the other pysumma objects, with some initialization of an object, configuration, and finally a run call. Before digging in I’ll describe at a high level detail how the Ostrich object works. The Ostrich object basically manages the initial state of the calibration and will write out all of the necessary files to actually run the calibration. It
only is a very thin wrapper around a subprocess call out to Ostrich itself. The Ostrich program will begin by setting initial parameter values and runs SUMMA through run_script.py, which is written by the Ostrich object. This run script will also handle the updating of the SUMMA parameter datastructures and evaluating the run with several metrics which can be used as loss functions. So far I have implemented KGE, MAE, and RMSE as well as a number of other helper pieces that I’ll
explain later.
As usual we will begin with some standard imports and configuration, along with loading in some data that we’ll use to determine default parameters.
[1]:
%pylab inline
%load_ext autoreload
%autoreload 2
%reload_ext autoreload
import pandas as pd
import pysumma as ps
veg_igbp = pd.read_csv('./VEGPARM_IGBP_MODIS_NOAH.TBL',
index_col=-1, skipinitialspace=True)
veg_igbp.index = veg_igbp.index.map(lambda x: x.strip().replace("'", ""))
soil_rosetta = pd.read_csv('./SOILPARM_ROSETTA.TBL',
index_col=-1, skipinitialspace=True)
soil_rosetta.index = soil_rosetta.index.map(lambda x: x.strip().replace("'", ""))
Populating the interactive namespace from numpy and matplotlib
Definition of the ps.Ostrich object¶
The ps.Ostrich object requires at least 3 inputs, along with optional specification of the python executable to use. The required arguments are: * ostrich_exe : the path to the Ostrich executable * summa_exe : the path to the SUMMA executable * file_manger : the path to the SUMMA setup file manager to calibrate * python_path : (optional) the path to the python executable that will be used to run SUMMA via pysumma.
The python_path may be necessary for you to specify because of conda/virtual environments. As usual, we define the object by instantiating it with these arguments.
[2]:
site = 'BE-Bra'
summa_exe = '/pool0/data/andrbenn/summa/bin/summa.exe'
ostrich_exe = '/pool0/home/andrbenn/data/naoki_calib_example/ostrich.exe'
python_exe = '/pool0/data/andrbenn/.conda/all/bin/python'
ostrich = ps.Ostrich(ostrich_exe, summa_exe, f'./{site}/file_manager.txt', python_path=python_exe)
Configuration of the ps.Ostrich object¶
Before the calibration can be started we have to fill out a bit more information. The method of doing so right now is to manually assign each of the required pieces of information. Hopefully in the future we can streamline this process while allowing for ease of customization, but for now consider the interface to be in flux. The first thing that needs to be set is some information about how to calculate the objective function at each calibration step. We do this with several pieces of
information, first setting the observation data file and the calibration variables in both the simulated and observed datasets. Then, you can specify a simple function to convert the observed and simulated data to match. In our case the observed data simply needs to be multiplied by negative one. Functions of this sort (lambdas) are the only supported method of conversion for the moment, and should be self contained (AKA not making any external function calls. Finally, we say that we want to
calibrate using root mean square error as our objective function and that we want to minimize it (or rather, that we don’t want to maximize it). As said earlier, the cost_function can be set to one of RMSE, MAE, or KGE for the moment. If setting the cost_function to KGE then you probably want to set maximize to True.
[3]:
ostrich.obs_data_file = f'/pool0/data/andrbenn/workspace/ostrich_example/{site}/forcings/{site}.nc'
ostrich.sim_calib_var = 'scalarLatHeatTotal'
ostrich.obs_calib_var = 'Qle_cor'
ostrich.import_strings = 'import numpy as np'
ostrich.conversion_function = lambda x: -x
ostrich.filter_function = lambda x: (x.isel(time=np.logical_and(x.time.dt.hour > 6, x.time.dt.hour < 20))
.sel(time=slice('2009-04-01', '2010-09-30')))
ostrich.cost_function = 'KGE'
ostrich.maximize = True
Now, we set a couple of the optimization algorithm parameters and interact with the ostrich object’s internal ps.Simulation object. First, we will set the max_iters and perturb_val - these control how many calibration runs to do and how “hard” to perturb our test parameters (which will be defined later). Then we set the run times of ostrich.simulation , which is simply a pysumma Simulation object wrapped inside of the Ostrich object. We will also retrieve the
local_attributes from the ostrich.simulation object, which contains the definitions of the soil and vegetation types which we will use to define our starting parameters.
[4]:
ostrich.max_iters = 100
ostrich.perturb_val = 0.2
ostrich.simulation.decisions['simulStart'] = '2009-01-01 23:30'
ostrich.simulation.decisions['simulFinsh'] = '2010-10-01 23:30'
attr = ostrich.simulation.local_attributes
Setting parameters and ranges¶
Once we have all of that we can work on setting up our default parameters from the soil and vegetation types. To do so, we will select out the soil and vegetation parameters for our specific run from the soil and vegetation tables loaded in at the beginning of this notebook. Then, I define some rooting depths that were not included in those tables for use later. Following that, I set some initial_values that will be used in the following cell when creating the calibration parameter objects.
[5]:
soil_params = soil_rosetta[soil_rosetta['SOILTYPINDEX'] == attr['soilTypeIndex'].values[0]]
veg_params = veg_igbp[veg_igbp['VEGTYPINDEX'] == attr['vegTypeIndex'].values[0]]
# Source: Zeng 2001 AMS
igbp_rooting_depths = {1: 1.8, 2: 3.0, 3: 2.0, 4: 2.0, 5: 2.4, 6: 2.5, 7: 3.10, 8: 1.7,
9: 2.4, 10: 1.5, 11: 0.01, 12: 1.5, 13: 1.5, 14: 1.5, 15: 0.01, 16: 4.0}
initial_values = {
'rootingDepth': igbp_rooting_depths[attr['vegTypeIndex'].values[0]],
'theta_res': soil_params['theta_res'].values[0],
'theta_sat': soil_params['theta_sat'].values[0],
'vGn_n': soil_params['vGn_n'].values[0],
'critSoilTranspire': soil_params['REFSMC'].values[0],
'k_soil': soil_params['k_soil'].values[0],
}
The cell following this text contains the first definition of basic calibration parameters, which are defined by
OstrichParamobjects. These are quite simple objects which are mainly used for converting values to the correct string template that will be used byOstrichinternally. The way that you construct a singleOstrichParamis to supply the parameter name as SUMMA sees it, the starting value and a range of values that Ostrich will search within. We provide a list of these
OstrichParams to the ostrich object in the calib_params attribute.
[6]:
ostrich.calib_params = [
ps.OstrichParam('k_soil', initial_values['k_soil'], (1e-7, 0.001)),
ps.OstrichParam('rootingDepth', initial_values['rootingDepth'], (0.01, 5.0)),
ps.OstrichParam('theta_res', initial_values['theta_res'], (0.001, 0.3)),
ps.OstrichParam('theta_sat', initial_values['theta_sat'], (0.3, 0.85)),
ps.OstrichParam('windReductionParam', 0.50, (0.0, 1.0)),
ps.OstrichParam('leafDimension', 0.04, (0.01, 0.1)),
]
Of course, this basic parameter search can lead up putting you into parameter space which is not physically possible, so we need to have the ability to “tie” parameters together with some constraints. To do so, you can use the
add_tied_parammethod on theostrichobject. Currently this only provides linear, bounded support between two other parameters, and no linked-tied parameters (that is a tied parameter can’t be used as a bound on another tied parameter). The syntax here is to
provide the tied parameter name, along with the parameter names that the tied parameter must be between. Ostrich will handle the rest from here.
[7]:
ostrich.add_tied_param('fieldCapacity', lower_bound='theta_res', upper_bound='theta_sat')
ostrich.add_tied_param('critSoilTranspire', lower_bound='theta_res', upper_bound='theta_sat')
Running and viewing output¶
Finally, we can write the configuration and run the optimization routine. For the moment I am leaving the write and run sections separate because the API is not stable and it is often useful to just write the configurationa and inspect it manually. At some point it will likely become incorporated directly into the run method as well, but currently this is the approach we take. Neither method requires any arguments. The run of this for 10 two year runs (as we specifed several code cells earlier) will take a bit to run. Following that we will simply print the standard output. It shows the output that you would normally see during runtime of Ostrich, but more statistics and diagnostics of the calibration will be incorporated into future versions of pysumma.
[8]:
ostrich.write_config()
[9]:
ostrich.run()
print(ostrich.stdout)
Starting up MPI required 0.000169 seconds
--------------------------------------------------------------------------
OSTRICH version 17.12.19 (Built Dec 19 2017 @ 12:26:43)
A computer program for model-independent calibration and optimization.
Author L. Shawn Matott
Copyright (C) 2007 L. Shawn Matott
This program is free software; you can redistribute
it and/or modify it under the terms of the GNU
General Public License as published by the Free
Software Foundation; either version 2 of the
License, or(at your option) any later version.
This program is distributed in the hope that it will
be useful, but WITHOUT ANY WARRANTY; without even
the implied warranty of MERCHANTABILITY or FITNESS
FOR A PARTICULAR PURPOSE. See the GNU General Public
License for more details.
You should have received a copy of the GNU General
Public License along with this program; if not,
write to the Free Software Foundation, Inc., 59
Temple Place, Suite 330, Boston, MA 02111-1307 USA
--------------------------------------------------------------------------
Ostrich Setup
Model : /pool0/data/andrbenn/workspace/ostrich_example/BE-Bra/calibration/run_script.py > OstExeOut.txt 2>&1
Algorithm : Dynamically Dimensioned Search Algorithm (DDS)
Objective Function : GCOP
Number of Parameters : 5
Number of Tied Params : 0
Number of Observations : 0
Seed for Random Nums. : 42
Number of Resp. Vars : 1
Number of Tied Resp. Vars : 1
Number of Constraints : 0
Penalty Method : Additive Penalty Method (APM)
Ostrich Run Record
trial best fitness k_soil_mtp rootingDepth_mtp windReductionParam_mtp leafDimension_mtp summerLAI_mtp trials remaining
1 -1.610490E-01 7.438520E-05 2.400000E+00 5.000000E-01 4.000000E-02 3.000000E+00 9.900000E+01
1...
Operation is complete
2 -1.971280E-01 1.439891E-04 3.118226E+00 4.878725E-01 3.634539E-02 2.524366E+00 9.800000E+01
DDS is searching for a better solution.
1... 2...
Operation is complete
4 -2.539060E-01 1.439891E-04 3.785837E+00 3.172336E-03 4.866133E-02 2.524366E+00 9.600000E+01
3...
Operation is complete
5 -2.832170E-01 1.439891E-04 3.785837E+00 2.186533E-01 4.866133E-02 8.954278E-01 9.500000E+01
DDS is searching for a better solution.
1... 2...
Operation is complete
7 -3.750430E-01 8.456853E-06 3.785837E+00 2.186533E-01 5.674160E-02 8.954278E-01 9.300000E+01
DDS is searching for a better solution.
1... 2... 3...
Operation is complete
10 -3.834180E-01 8.456853E-06 3.785837E+00 1.552120E-01 9.770673E-02 8.954278E-01 9.000000E+01
DDS is searching for a better solution.
1... 2... 3...
Operation is complete
13 -3.834180E-01 8.456853E-06 3.785837E+00 1.552120E-01 9.770673E-02 1.857542E+00 8.700000E+01
4...
Operation is complete
14 -4.174280E-01 8.456853E-06 4.663890E+00 1.552120E-01 9.623314E-02 2.710123E+00 8.600000E+01
DDS is searching for a better solution.
1... 2... 3...
Operation is complete
17 -4.174500E-01 8.456853E-06 4.664965E+00 1.552120E-01 9.623314E-02 2.710123E+00 8.300000E+01
DDS is searching for a better solution.
1... 2...
Operation is complete
19 -4.506680E-01 1.865815E-04 4.664965E+00 4.455703E-01 9.623314E-02 8.730342E-01 8.100000E+01
DDS is searching for a better solution.
1... 2... 3...
Operation is complete
22 -4.927490E-01 2.260646E-04 4.664965E+00 6.988841E-01 9.623314E-02 8.730342E-01 7.800000E+01
DDS is searching for a better solution.
1... 2... 3... 4... 5... 6... 7... 8... 9... 10...
11... 12...
Operation is complete
34 -4.927490E-01 2.260646E-04 4.664965E+00 6.988841E-01 9.623314E-02 1.659186E+00 6.600000E+01
DDS is searching for a better solution.
1... 2...
Operation is complete
36 -5.012780E-01 1.428445E-04 4.664965E+00 7.456359E-01 9.623314E-02 1.659186E+00 6.400000E+01
3...
Operation is complete
37 -5.012780E-01 1.428445E-04 4.664965E+00 7.456359E-01 9.623314E-02 6.370261E-01 6.300000E+01
DDS is searching for a better solution.
1... 2... 3...
Operation is complete
40 -5.095020E-01 2.684462E-05 4.664965E+00 7.456359E-01 9.623314E-02 6.370261E-01 6.000000E+01
DDS is searching for a better solution.
1... 2... 3...
Operation is complete
43 -5.248270E-01 7.023297E-06 4.664965E+00 7.456359E-01 9.623314E-02 6.370261E-01 5.700000E+01
4...
Operation is complete
44 -5.301650E-01 7.023297E-06 4.955542E+00 7.456359E-01 9.623314E-02 1.246376E+00 5.600000E+01
5...
Operation is complete
45 -5.301650E-01 7.023297E-06 4.955542E+00 7.456359E-01 9.623314E-02 6.007198E-01 5.500000E+01
DDS is searching for a better solution.
1... 2... 3...
Operation is complete
48 -5.390430E-01 7.023297E-06 4.955542E+00 8.030981E-01 9.623314E-02 6.007198E-01 5.200000E+01
4...
Operation is complete
49 -5.460650E-01 7.023297E-06 4.955542E+00 8.504111E-01 9.623314E-02 6.007198E-01 5.100000E+01
DDS is searching for a better solution.
1... 2...
Operation is complete
51 -5.607890E-01 7.023297E-06 4.955542E+00 9.559419E-01 9.623314E-02 6.007198E-01 4.900000E+01
DDS is searching for a better solution.
1... 2... 3... 4...
Operation is complete
55 -5.607890E-01 7.023297E-06 4.955542E+00 9.559419E-01 9.623314E-02 2.980191E+00 4.500000E+01
DDS is searching for a better solution.
1... 2... 3... 4...
Operation is complete
59 -5.607890E-01 7.023297E-06 4.955542E+00 9.559419E-01 9.623314E-02 3.080925E+00 4.100000E+01
DDS is searching for a better solution.
1... 2... 3... 4...
Operation is complete
63 -5.621310E-01 7.023297E-06 4.955542E+00 9.660100E-01 9.623314E-02 3.080925E+00 3.700000E+01
DDS is searching for a better solution.
1... 2... 3...
Operation is complete
66 -5.621310E-01 7.023297E-06 4.955542E+00 9.660100E-01 9.623314E-02 3.885631E+00 3.400000E+01
DDS is searching for a better solution.
1... 2... 3... 4... 5...
Operation is complete
71 -5.621310E-01 7.023297E-06 4.955542E+00 9.660100E-01 9.623314E-02 1.770040E+00 2.900000E+01
6...
Operation is complete
72 -5.621310E-01 7.023297E-06 4.955542E+00 9.660100E-01 9.623314E-02 6.265755E-01 2.800000E+01
DDS is searching for a better solution.
1... 2...
Operation is complete
74 -5.621310E-01 7.023297E-06 4.955542E+00 9.660100E-01 9.623314E-02 2.618509E+00 2.600000E+01
DDS is searching for a better solution.
1... 2... 3...
Operation is complete
77 -5.621310E-01 7.023297E-06 4.955542E+00 9.660100E-01 9.623314E-02 1.749049E+00 2.300000E+01
DDS is searching for a better solution.
1... 2... 3...
Operation is complete
80 -5.621310E-01 7.023297E-06 4.955542E+00 9.660100E-01 9.623314E-02 1.164108E+00 2.000000E+01
4...
Operation is complete
81 -5.621310E-01 7.023297E-06 4.955542E+00 9.660100E-01 9.623314E-02 3.619872E+00 1.900000E+01
DDS is searching for a better solution.
1... 2...
Operation is complete
83 -5.621310E-01 7.023297E-06 4.955542E+00 9.660100E-01 9.623314E-02 1.426859E+00 1.700000E+01
DDS is searching for a better solution.
1... 2...
Operation is complete
85 -5.658310E-01 7.023297E-06 4.955542E+00 9.942457E-01 9.623314E-02 1.426859E+00 1.500000E+01
DDS is searching for a better solution.
1... 2...
Operation is complete
87 -5.658310E-01 7.023297E-06 4.955542E+00 9.942457E-01 9.623314E-02 4.554346E+00 1.300000E+01
DDS is searching for a better solution.
1... 2... 3...
Operation is complete
90 -5.658310E-01 7.023297E-06 4.955542E+00 9.942457E-01 9.623314E-02 5.749287E+00 1.000000E+01
DDS is searching for a better solution.
1... 2... 3... 4...
Operation is complete
94 -5.658310E-01 7.023297E-06 4.955542E+00 9.942457E-01 9.623314E-02 7.144379E+00 6.000000E+00
DDS is searching for a better solution.
1... 2... 3... 4...
Operation is complete
98 -5.658310E-01 7.023297E-06 4.955542E+00 9.942457E-01 9.623314E-02 4.982360E+00 2.000000E+00
DDS is searching for a better solution.
1... 2...
Operation is complete
100 -5.658310E-01 7.023297E-06 4.955542E+00 9.942457E-01 9.623314E-02 4.982360E+00 0.000000E+00
Optimal Parameter Set
Objective Function : -5.658310E-01
k_soil_mtp : 7.023297E-06
rootingDepth_mtp : 4.955542E+00
windReductionParam_mtp : 9.942457E-01
leafDimension_mtp : 9.623314E-02
summerLAI_mtp : 4.982360E+00
Summary of Constraints
Algorithm Metrics
Algorithm : Dynamically-Dimensioned Search Algorithm (DDS)
Desired Convergence Val : N/A
Actual Convergence Val : N/A
Max Generations : 100
Actual Generations : 100
Peterbation Value : 0.200000
Total Evals : 101
Telescoping Strategy : none
Algorithm successfully converged on a solution, however more runs may be needed
Shutting down MPI required 0.000000 seconds
Ostrich Error Report for Processor 0
A total of 1 errors and/or warnings were reported
FILE I/O ERROR : No constraints specified.
num CTORS: 17
num DTORS: 17
[ ]: